

Özet:
Merhaba,
Bu makalede hayatımızın her noktasına giren yapay zeka kavramının SQL Server’daki karşılığı olan Vektör Arama kavramını ve henüz SQL Server On Prem sistemlerde olmayan vektör arama işlemini kendi yazdığım T-SQL kodları ile nasıl yaptığımı öğrenmiş olacaksınız. Makale oldukça uzun olduğu için burada anlatılanları okuduktan sonra neler öğreneceğinizi madde madde buraya yazmak istedim. Ona göre ilginizi çekip çekmediğine karar verebilirsiniz.
1.Vektör arama işlemi ve vektör kavramı nedir?
2.SQL Server’da bildiğimiz Select * from Items where title_ like ‘Lenovo%laptop%çanta%’ şeklinde metin arama yerine
“Lenovo marka bir notebook çantası arıyorum” dendiğinde prompt yazar gibi arama işlemi nasıl yapılır?
Ya da Türkçe bir verisetinde “I am looking for a notebook backpack with Lenovo Brand” yazdığında da aynı sonuç nasıl getirilir?
3.Bir metin nasıl vektörize edilir?
4.Cosine distance nedir? İki vektörün benzerliği nasıl hesaplanır?
5.SQL Server’da nasıl hızlı bir şekilde vektör arama işlemi gerçekleştirilir?
6.İleri seviye performans için Clustered Columnstore Index ve Ordered Clustered Columnstore index nasıl kullanılır?
Not:Burada kullanmış olduğum scriptleri ve kullandığım database i github sayfamda paylaştım.
Buradan inceleyebilirsiniz.
https://github.com/ocolakoglu/SQL-Server-Works/blob/SQL-Server-On-Prem-Vector-Search/README.md
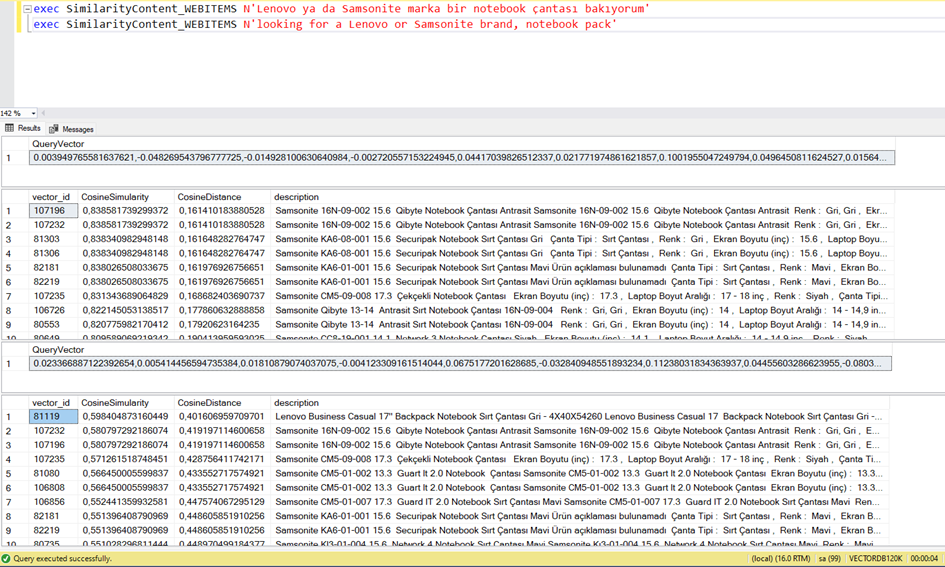
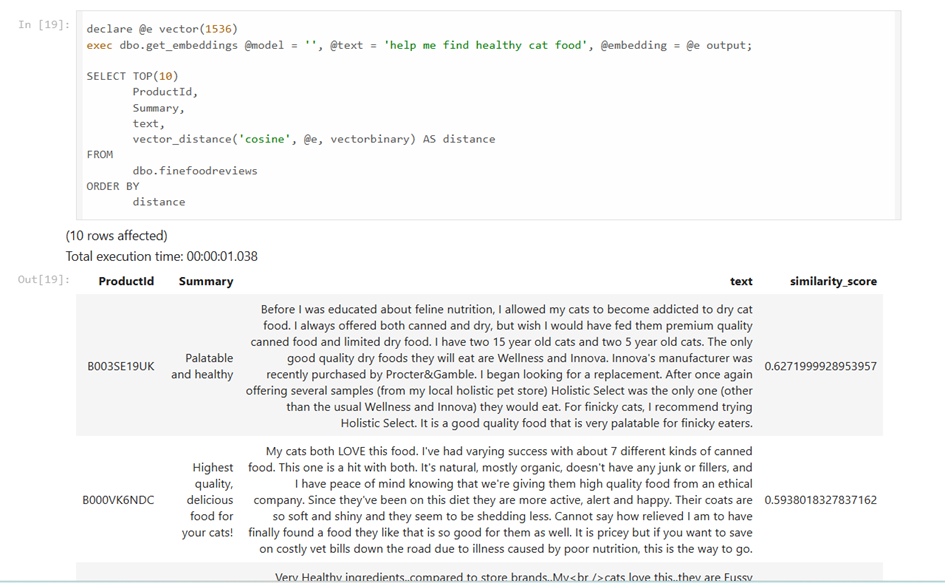
Şuraya da bir final görseli bırakayım belki sonuna kadar okumanız için motive eder. 🙂 Filmin sonunda işte aşağıdaki gibi bir arama yapabileceksiniz hem de on prem ortamda. Bu önemli, zira Microsoft’un şu an on prem SQL Server’da böyle bir vektör arama özelliği yok.

1.Giriş
SQL Server’da arama işlemi yaparken yaptığımız işlem bellidir değil mi?
Örneğin “Lenovo Notebook Çantası” arama yaptığımız ifade bu olsun.
Bunu şu şekilde arayabiliriz.
SELECT * FROM WEBITEMS WHERE TITLE_ LIKE '%LENOVO NOTEBOOK ÇANTASI%'
Buradan bir sonuç dönmediğini görüyoruz çünkü bu üç kelimenin bu şekilde yan yana geçtiği bir ürün yok.

Bu durumda bu üç kelime ayrı ayrı yerlerde geçebilir ama aynı cümlede olmalı mantığı ile şu şekilde yazabiliriz.
SELECT * FROM WEBITEMS WHERE TITLE_ LIKE N'%Lenovo%' AND TITLE_ LIKE N'%Notebook%' AND TITLE_ LIKE N'%Çantası%'
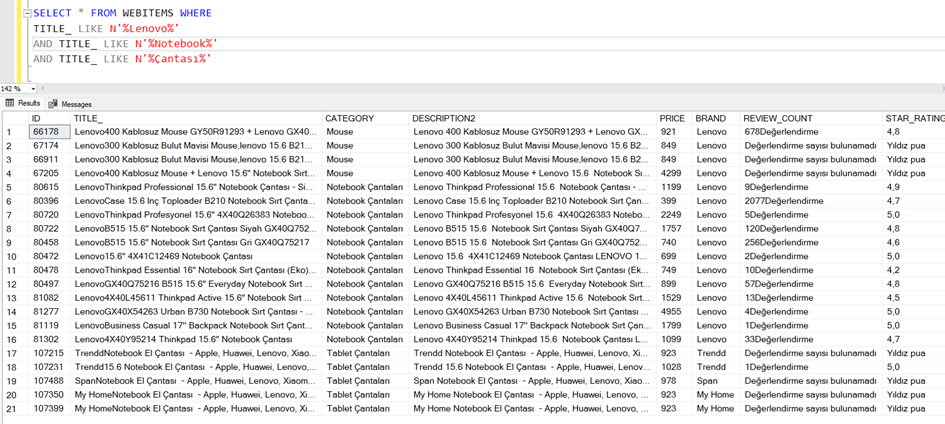
Görüldüğü gibi burada bu formata uyan bazı kayıtlar var.
Ama bir de şöyle bakalım. “Çantası” kelimesi “Çanta” kökünden geliyor. Acaba “Çantası” değil de kökünü yazsak nasıl olur?
SELECT * FROM WEBITEMS WHERE
TITLE_ LIKE N'%Lenovo%'
AND TITLE_ LIKE N'%Notebook%'
AND TITLE_ LIKE N'%Çanta%'
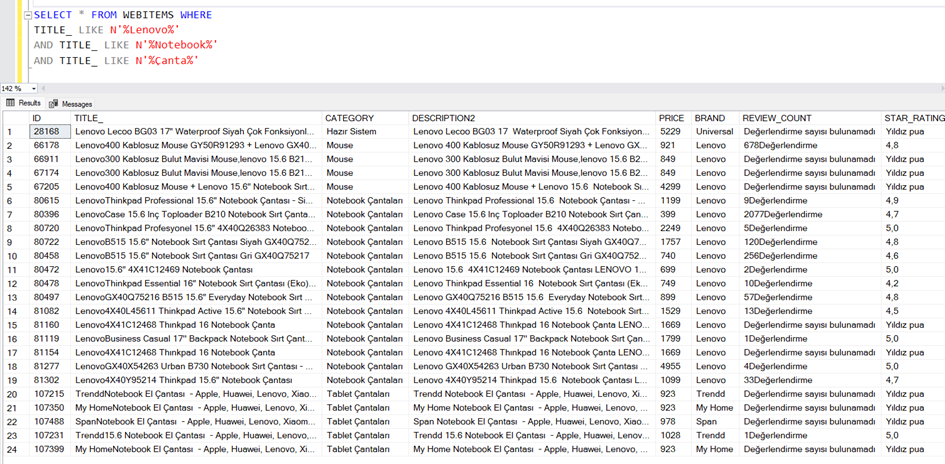
Gördüğünüz gibi bu kez 24 satır döndü.
Başka bir alternatif yöntem de fulltext search arama işlemi ile bu aramayı gerçekleştirmek.
SELECT * FROM WEBITEMS WHERE
CONTAINS(TITLE_,N'Lenovo')
AND CONTAINS(TITLE_,N'Notebook')
AND CONTAINS(TITLE_,N'Çantası')Tabi ki fulltext arama işlemi diğerlerine göre çok çok hızlı çalışan bir yapı.
Şimdi buraya kadar mevcut bilgilerimizin üzerinden geçtik.
2.Vektör arama işlemi ve vektör kavramı
Şimdi sizleri yepyeni bir kavram ile tanıştıracağım. “Vector Search”
Özellikle GPT’ler dil modelleri yapay zeka gibi kavramlar çıktıktan sonra oyunun kuralları iyice değişti. Biz artık bir çok işimizi prompt yazarak hallediyoruz. Çünkü yapay zeka prompt ile ne istediğimizi anlayabilecek kadar akıllı.
Peki bu noktada SQL Server tarafında neler oluyor?
Orada da Vector Store ve Vector Search kavramları var.
Temel anlamda olay şu aslında.
Bir metin ifadeyi belli uzunlukta (ben burada 768 elemanlı olarak kullandım) bir vektör dizisine çeviriyor ve veriyi bu şekilde tutuyor.
Buradaki vektör 768 tane ondalık sayıdan oluşuyor.
Tabloda metin olarak tuttuğumuz bir kolonun tüm satırlarını vektöre çevirip içeride vektör olarak saklıyoruz ve arama yapmak istediğimizde arama yapmak istediğimiz metin ifadeyi de vektöre çevirip tüm satırlar için bu iki vektör arasındaki benzerliği hesaplayıp en yakın olanı bulmaya çalışıyoruz.
Örnek olarak arama yapmak istediğimiz cümle şöyle olsun.
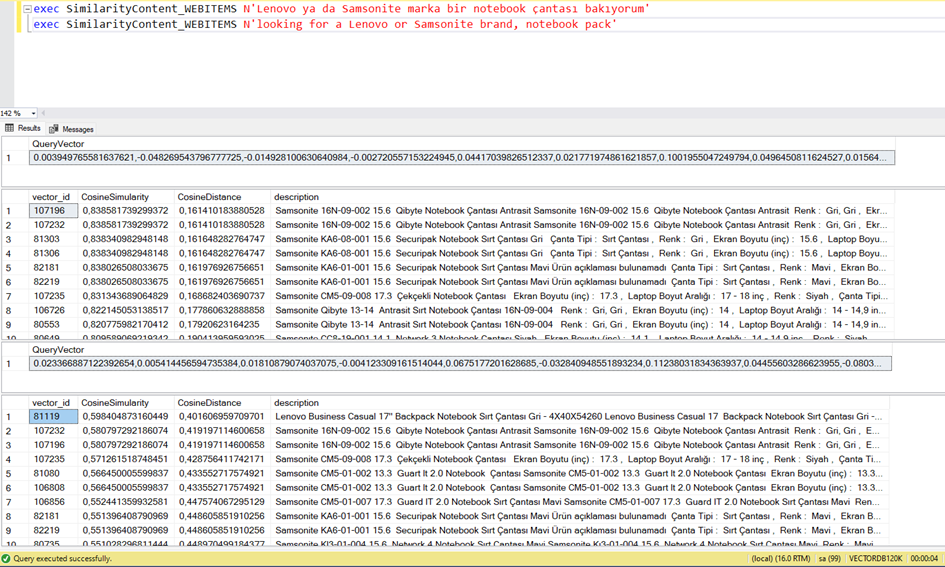
“Lenovo ya da Samsonite marka bir notebook çantası arıyorum.”
Bunu vektöre çevirdiğimizde aşağıdaki sonucu elde ediyoruz.
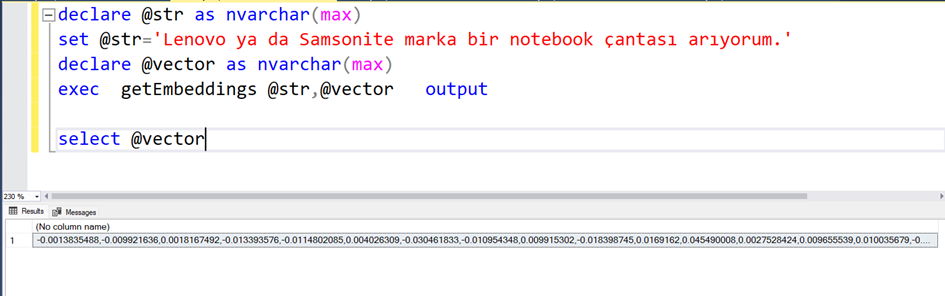
“Lenovo ya da Samsonite marka bir notebook çantası arıyorum.”
İfadesinin vektörize edilmiş (embed edilmiş hali)
-0.0013835488,-0.009921636,0.0018167492,-0.013393576,-0.0114802085,0.004026309,-0.030461833,-0.010954348,0.009915302,-0.018398745,0.0169162,0.045490008,0.0027528424,0.009655539,0.010035679,-0.026533727,0.021325817,-0.020641567,0.009579511,0.000736916,-0.028003598,-0.013900429,0.020894993,-0.0065954174,0.0020575041,0.0043525957,0.02059088,…
Vektöre çevirme işini getEmbeddings isimli procedure yapıyor.
Bu procedure SQL Server içerisinde olan bir procedure değil. AzureSQL’de bu özellik var ancak on premde yok.
Burada Azure OpenAI hizmetine bağlanarak vektöre çevirme işlemini gerçekleştiriyor.
Şimdi iki vektörün karşılaştırmasını nasıl yaptığımıza bakalım.
Burada cosine distance isimli bir formül kullanıyoruz.
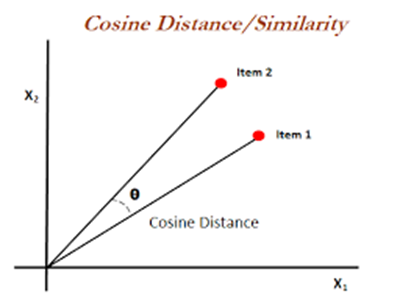
Vektör Benzerlik Karşılaştırma Cosine Distance
Cosine distance, iki vektör arasındaki benzerliği ölçmek için kullanılan bir mesafe metriğidir. İki vektör arasındaki açıyı temel alır.
Vektörler aynı yöne baktığında benzer kabul edilirler, farklı yönlere baktıkça aralarındaki mesafe artar.
Basit tanımıyla:
- Cosine distance, iki vektör arasındaki açının cosinüsünü hesaplar ve benzerlik derecesini verir.
- Açının cosinüsü ne kadar büyükse (1’e yakınsa), iki vektör o kadar benzerdir.
- Cosine distance değeri 0’a yaklaştıkça vektörler birbirine benzer, 1’e yaklaştıkça farklıdır.
Özellikle metin ve belge gibi büyük veri kümelerinde, içerik benzerliğini ölçmek için kullanılır.
Tabi burada vektör dediğimiz kavram 768 elemanlı bir dizi olduğu için vektörün tüm elemanlarını içeren bir konudan bahsediyoruz.
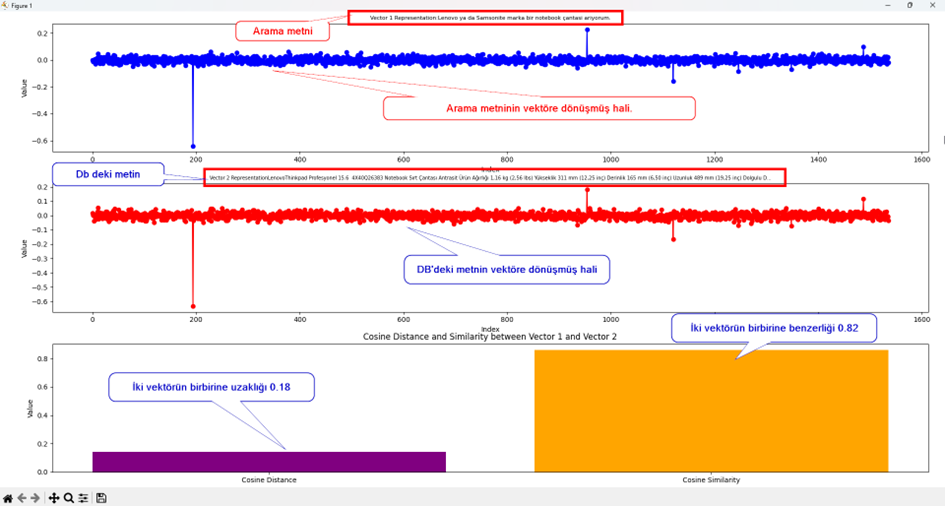
Aşağıdaki resimde de görüldüğü gibi
Arama cümlesi olan
“Lenovo ya da Samsonite marka bir notebook çantası arıyorum.”
İle Veritabanındaki kayıt olan
“LenovoThinkpad Profesyonel 15.6 4X40Q26383 Notebook Sırt Çantası Antrasit Ürün Ağırlığı 1,16 kg (2,56 lbs) Yükseklik 311 mm (12,25 inç) Derinlik 165 mm (6,50 inç) Uzunluk 489 mm (19,25 inç) Dolgulu Defter Bölmesi Evet (U x D x Y) 381 x 262 x 34 mm’ye (14,98 x 10,31 x 1,33 inç) kadar uyar Siyah renk Marka ThinkPad Ekran Boyutu (inç) : 15.6 , Laptop Boyut Aralığı : 15 – 16 inç , Renk : Antrasit , Çanta Tipi : Sırt Çantası , Hacim (L) : 16.8 , Malzeme : Polyester , Yan Şişe Gözü : Yok , Genişletebilirlik : Yok , Göğüs Kilidi : Yok , Bel Kilidi : Yok , USB Portu : Yok , Garanti Süresi (Ay) : 24 , Yurt Dışı Satış : Yok , Stok Kodu : HBCV00000UDIJ3 Değerlendirme Sayısı:5Değerlendirme Marka:Lenovo Satıcı:Kraft Online Satıcı puanı:9,5”
Cümlesinin vektöre çevrilmiş hallerinin vektörlerini ve aradaki benzerliği görüyorsunuz.
Veritabanından vektörler üzerinden benzerlik araması yapabiliyor olmak bize veritabanını bir chatbot gibi kullanma imkanı sunar.
Bu durumda prompt yazar gibi arama işlemi gerçekleştirebiliriz. Zaten Azure SQL üzerinde hali hazırda böyle bir komut var.
İki vektör arasındaki cosine distance değerini ve buna bağlık olarak benzerliği hesaplıyor.
Konu ile alakalı makaleye aşağıdaki linkten ulaşabilirsiniz.
Burada Azure SQL üzerinde hali hazırda olan bir durumu On Prem SQL Server üzerinde gerçekleştirmeye çalışacağız.
Öncelikle vektöre çevirme işlemini nasıl yapacağımıza bakalım.
Elimizde şöyle bir tablo var.
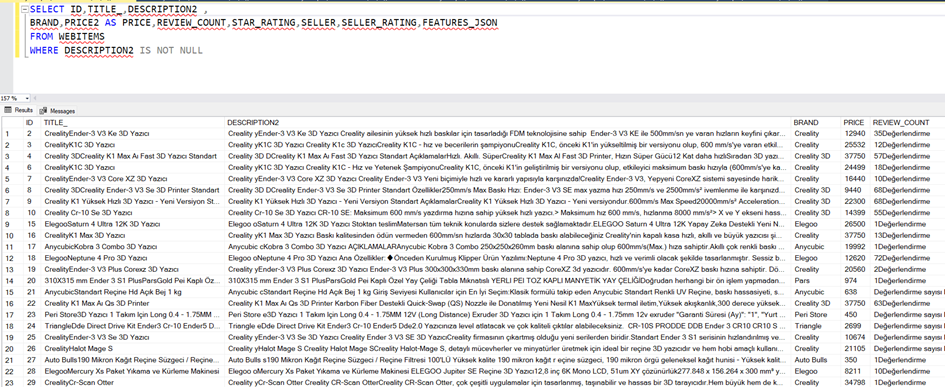
Bu tabloda DESCRIPTION2 alanı ürünün tüm özelliklerini içinde barındıran yapısal olmayan bir metin alan. Bu alan üzerinde arama yapacağımız için bu alanı vektöre çevirmeliyiz.
SQL Server üzerinde doğrudan vektöre çeviren bir kod şimdilik olmadığı için burada bunu dışarıdan bir eklenti ile yapacağız. Burada çeşitli dil modelleri var. Örneğin, Azure Open AI servisini kullanabiliriz.
Bunun için şöyle bir procedure yazdım.
Kullanımı da bu şekilde,
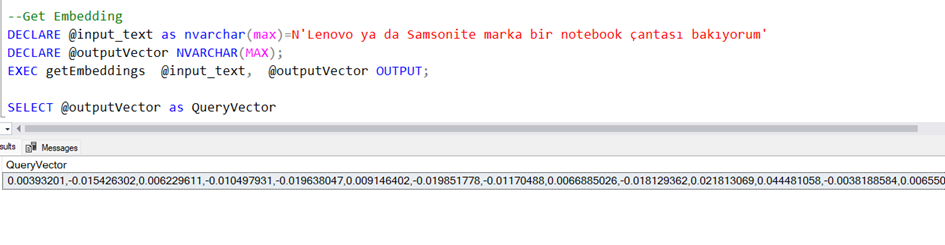
Buradaki vektör “text-embedding-ada-002” modelini kullanıyor ve 1536 elemanlı vektör oluşturuyor.
Alternatif olacak Azure kullanmadan Python da kendimiz bir kod yazabiliriz ve başka bir model üzerinden vektör dönüşümü yapabiliriz.
from flask import Flask, request, jsonify
from sentence_transformers import SentenceTransformer
# Flask uygulaması ve model başlatma
app = Flask(__name__)
model = SentenceTransformer('all-mpnet-base-v2')
# Vektör döndüren endpoint tanımlama
@app.route('/get_vector', methods=['POST'])
def get_vector():
# JSON isteğinden metni al
data = request.get_json()
if 'text' not in data:
return jsonify({"error": "Request must contain 'text' field"}), 400
try:
# Metni vektöre çevirme
embedding = model.encode(data['text'])
# Embedding vektörünü listeye çevirip JSON olarak döndürme
return jsonify({"vector": embedding.tolist()})
except Exception as e:
return jsonify({"error": str(e)}), 500
# Flask uygulamasını çalıştırma
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000)
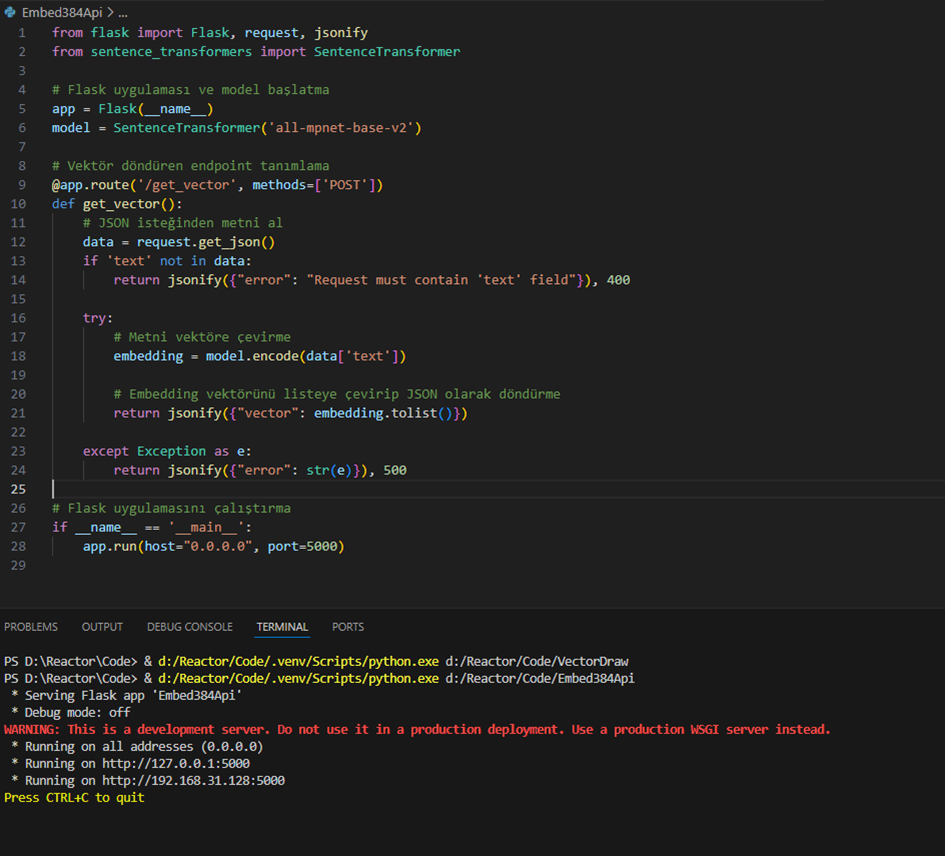
Bu kod içine string ifade alan ve sonuç olarak “all-mpet-base-v2” modeline göre vektör çevrimi yapan bir kod.768 elemanlı vektör oluşturuyor.
Şimdi bu apiyi SQL’den çağıracak TSQL kodunu yazalım.
Onun da kullanımı bu şekilde.
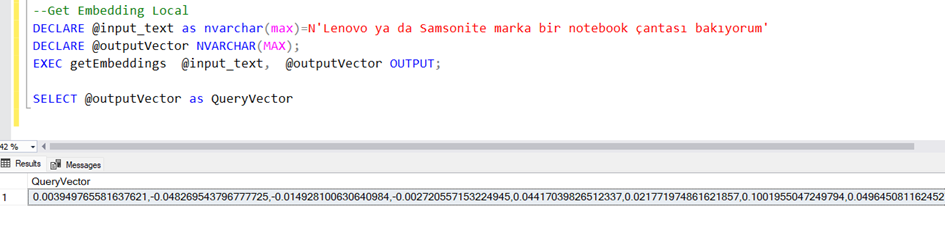
Şimdi tabloya eklediğimiz alan için bu vektöre çevirme işlemini gerçekleştirelim.
Ben burada local hizmeti kullanıyor olacağım. Aşağıdaki sorgu tablodaki tüm satırlar için VECTOR768 (768 elemanlı bir alan olduğu için bu ismi kullandım) alanını vektöre çevirip update eder.
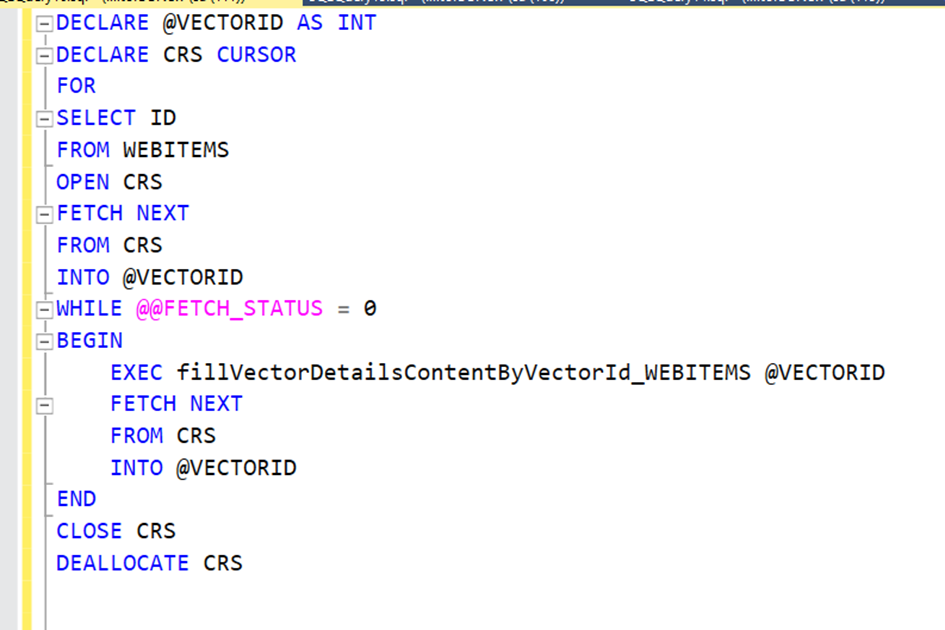
DECLARE @ID AS INT
DECLARE @STR AS NVARCHAR(MAX)
DECLARE CRS CURSOR FOR SELECT ID,DESCRIPTION2 FROM WEBITEMS WHERE DESCRIPTION2 IS NOT NULL
OPEN CRS
FETCH NEXT FROM CRS INTO @ID,@STR
WHILE @@FETCH_STATUS =0
BEGIN
DECLARE @VECTOR AS NVARCHAR(MAX)
EXEC getEmbeddingsLocal @STR,@VECTOR OUTPUT
UPDATE WEBITEMS SET VECTOR=@VECTOR WHERE ID=@ID
FETCH NEXT FROM CRS INTO @ID,@STR
END
CLOSE CRS
DEALLOCATE CRS
Uzun bir işlemden sonra artık vektör kolonumuz hazır ve şimdi bu kolon üzerinde similarity search yapacağız.
Cosine Distance Hesaplama Yöntemi
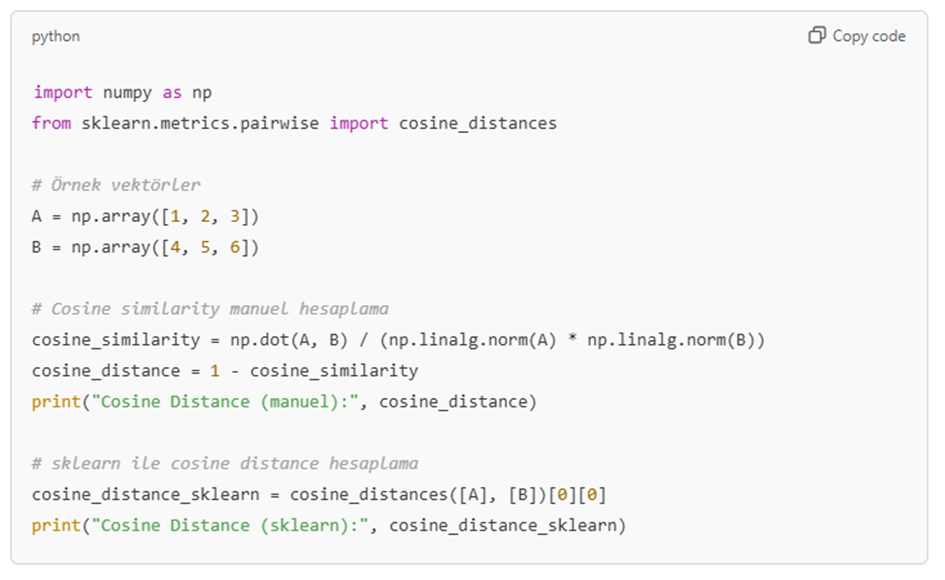
Cosine Distance şöyle hesaplanır.
Örnek olarak 3 elemanlı iki vektörümüz olsun.
Vector1=[0.5,0.3,-0.8]
Vector2=[-0.2,0.4,0.9]
Burada cosine distance şöyle hesaplanır.
Her elemanın birbiri ile çarpımının toplamı @dotproduct
@dotproduct=(0.5x(-0.2))+(0.3×0.4)+(-0.8×0.9) =-0.7
Her elemanın karelerinin toplamı @magnitude1, @magnitude2
@magnitude1=(0.5×0.5)+(0.3×0.3)+(-0.8x-0.8)=0.98
@magnitude2=(-0.2x-0.2)+( 0.4×0.4)+( 0.9×0.9)=1.01
Benzerlik hesaplamak için ise
@similarity=@dotproduct / (SQRT(@magnitude1) * SQRT(@magnitude2));
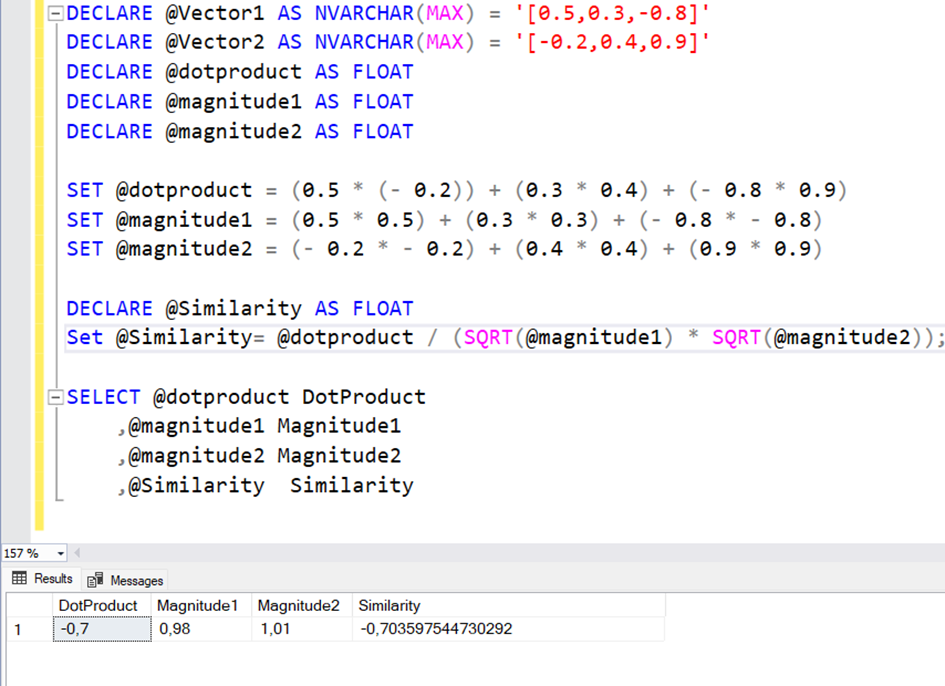
TSQL ile Cosine Distance Hesaplama Örneği
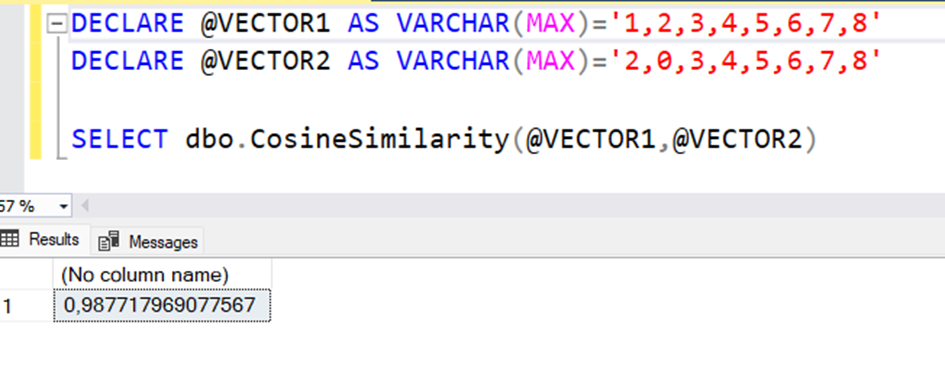
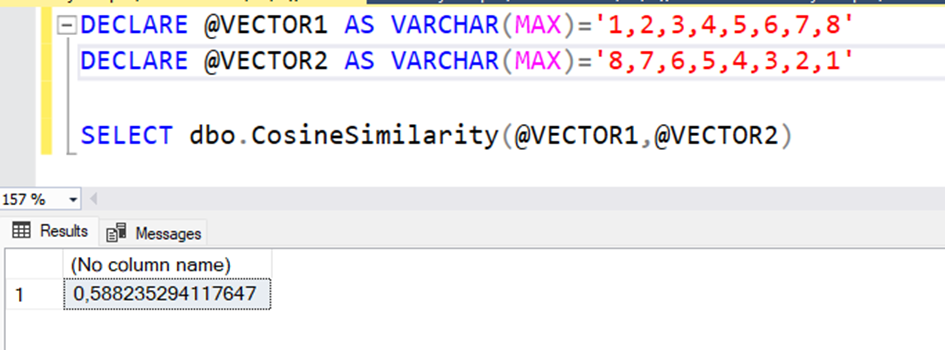
Şimdi db deki bir vektör ile bir string ifadeyi karşılaştıralım.
--Arama cümlesi oluşturuluyor ve vektöre çevriliyor
DECLARE @query AS NVARCHAR(MAX) = 'Bir notebook çantası bakıyorum';
DECLARE @searchVector AS NVARCHAR(MAX);
exec getEmbeddingsLocal @query,@searchVector output
--Veritabanından seçilen 1 satırdaki DESCRIPTION2 alanı vektöre çevriliyor
DECLARE @dbText as nvarchar(max)
DECLARE @dbVector as nvarchar(max)
SELECT @dbText=DESCRIPTION2 FROM WEBITEMS WHERE ID=80472
exec getEmbeddingsLocal @dbText,@dbVector output
--Vektör ve Cümeleler yazdırılıyor
select @query Query,@searchVector SearchVector
select @dbText DBText,@dbvector DBVector
--İki vektörün benzerlik ve Cosine distance değerleri hesaplanıyor
Select dbo.CosineSimilarity(@searchVector,@dbvector) Similarity,1 -dbo.CosineSimilarity(@searchVector,@dbvector) CosineDistance
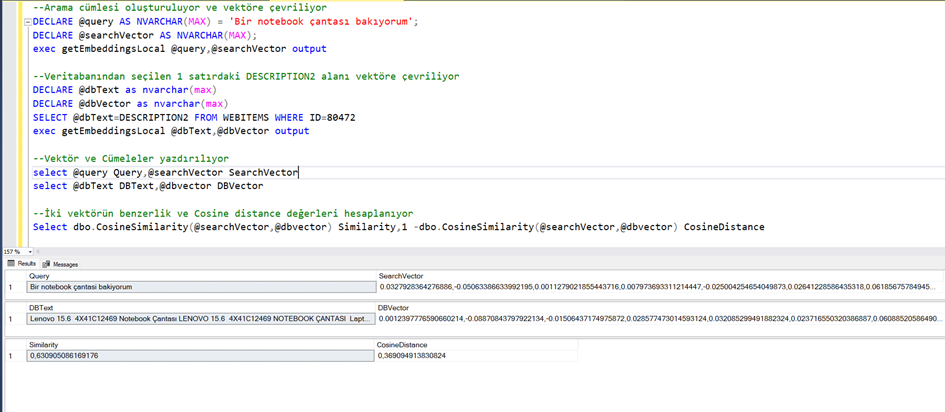
Görüldüğü gibi bu iki metin ifadenin birbiri ile olan benzerliği 0.63 çıktı. Burada biz şu anda sadece bir kayıt ile benzerlik hesapladık. Oysa olması gereken veritabanındaki tüm kayıtlar içinde bu benzerliğin hesaplanarak en çok benzeme oranına sahip olana göre belli bir sayıda kaydın gelmesi.
Veritabanında 100.000’den fazla kayıt olduğuna göre bu fonksiyonun 100.000’den fazla kez çalışması gerekiyor. Bu da ciddi bir performans sorunu. 1000 satır kayıt için çalıştıralım.
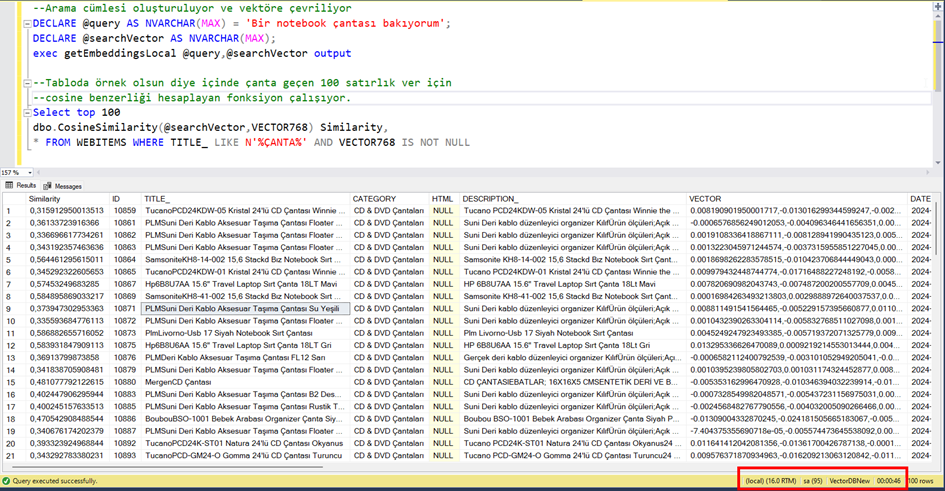
Görüldüğü gibi 100 satırlık veri için bile 46 saniye sürdü. Bu da 100 bin satır için yaklaşık 46×1000=46.000 saniye o da yaklaşık 12 saatlik bir süre demek.
Bu sürenin bu kadar olması anormal değil.
Zira arka planda yaptığımız şey tam olarak şöyle.
1.@dotProduct hesaplanırken Vektörlerin eleman sayısı kadar (Bizdeki sayı 768) elemanların birbiri ile çarpım işlemi var ve sonra bunların toplama işlemi var.
768 Çarpım+768 toplama=1536 işlem
2.Her bir vektör için elemanların karelerinin alınarak toplamının hesaplanması işlemi var.
Her iki vektör için kare alma işlemi 768+768=1536 işlem
3.Son olarak da bu toplamların üzerinden yapılan
@dotproduct / (SQRT(@magnitude1) * SQRT(@magnitude2))
İşlem var ama bu önemli değil zira 1 kez gerçekleşiyor.
Bu durumda her 768 elemanlı bir vektör için her bir satırda 1536+1536=3072 işlem gerçekleşiyor.
100 bin satırlık bir tabloda bu sayı 100.000×3072=307.200.000 (Yaklaşık 300 milyon) matematiksel işlem anlamına gelir. Dolayısıyla bu kadar uzun sürmesi mümkündür.
Kısacası bu şekilde hesaplama yapmak bizim için çok sağlıklı değil.
Bu işi hızlandırmak için ne yapmalı?
Evet şimdi gelelim bu işi nasıl hızlandıracağımıza.
SQL Server dikeyde verilerle çalışmayı sever diye çok kez söylemiştim.
Dikeyden kastım satırlardaki veriler ve doğru indexler.
Oysa bizim elimizdeki vektör veri nerede? Yan yana virgül ile ayırt edilen 768 bazen de kullanılan dil modeline göre 1536 tane yatayda veri.
SQL Server yatay veride iyi değildir. O zaman bu yatay veriyi dikeye çevirsek nasıl olur?
Yani vektörün her bir elemanını bir satır olarak sisteme eklesek.
Bunun için bir tablo oluşturacağız.
CREATE TABLE vectordetails_WEBITEMS(
id int IDENTITY(1,1) NOT NULL,
vector_id [int] NOT NULL,
value_ float NULL,
key_ int NOT NULL
) ON [PRIMARY]Burada bir ürün için ID değerini burada Vector_id olarak tutacağız. Vektör elemanının sıra numarasını key_, değerini de value_ olarak tutacağız.
Örnek olarak, ID si 80472 olan ürünü inceleyelim.

Burada virgül ile ayırt edilen verileri satır satır okur isek,
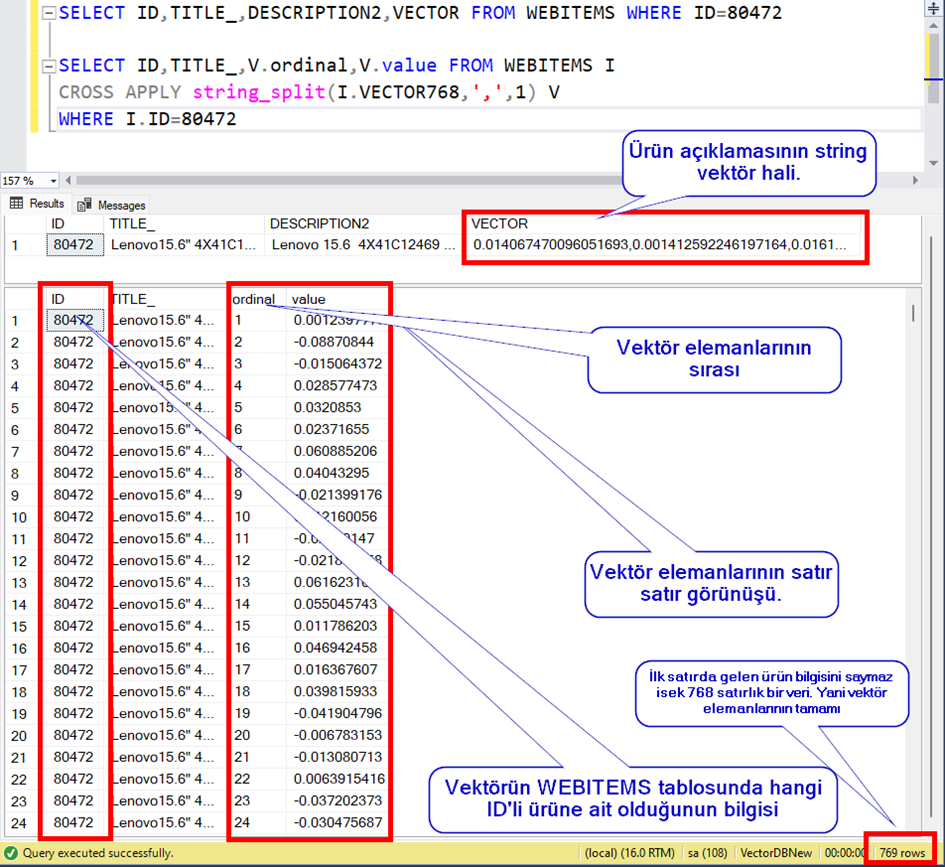
Şimdi her bir ürün için bunu tabloya yazacak bir procedure yazalım.
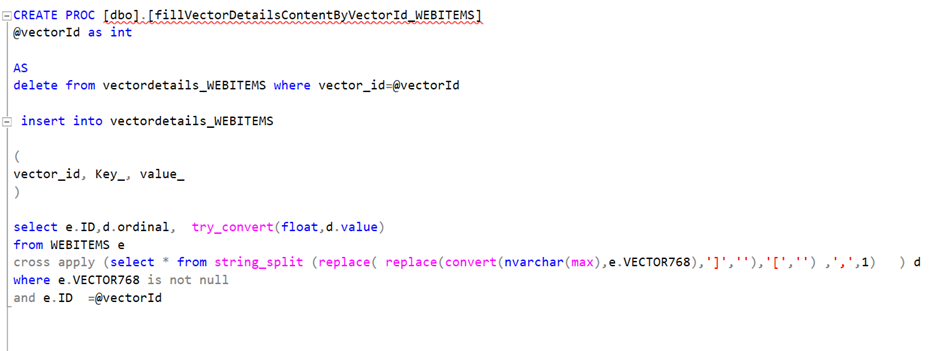
Şimdi tüm ürünler için bu procedürü çağıralım.
Cosine Simularity Hızlı Hesaplama
Evet artık buraya kadar geldikten sonra sırada hızlı şekilde benzerlik hesaplama işlemi var. Bunun için yazdığım bir TSQL kodu var.
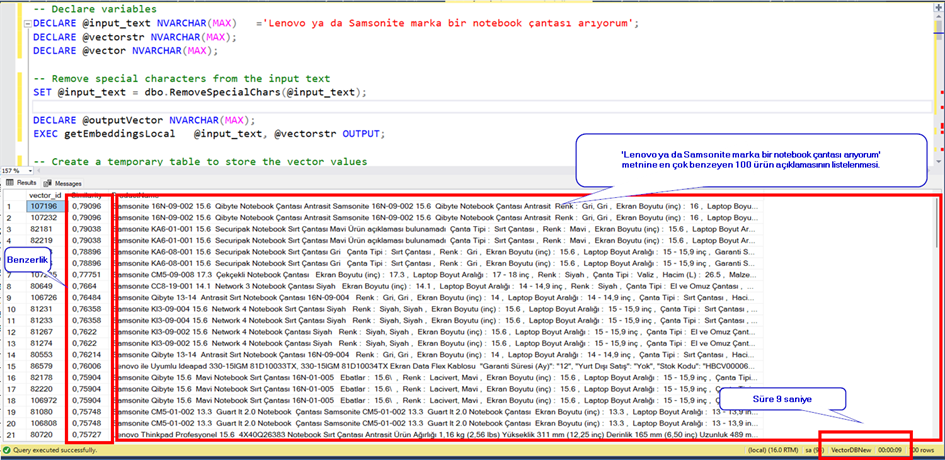
Sorgumuz güzel çalışıyor görünüyor ancak süre 9 saniye. Bunu biraz hızlandırmak için tablomuza birkaç index ekleyelim.
Create Index IX01 on vectordetails_WEBITEMS(key_) include (vector_id,value_,ID)
Create Index IX02 on vectordetails_WEBITEMS(key_,vector_id) include (value_,ID)

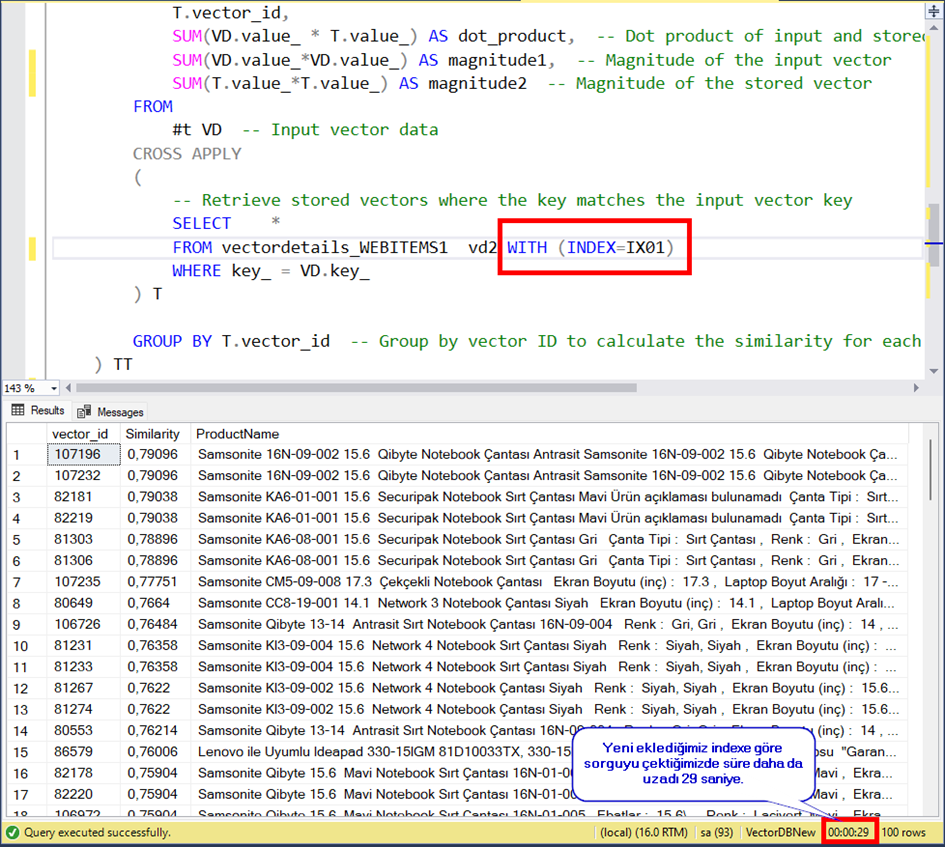
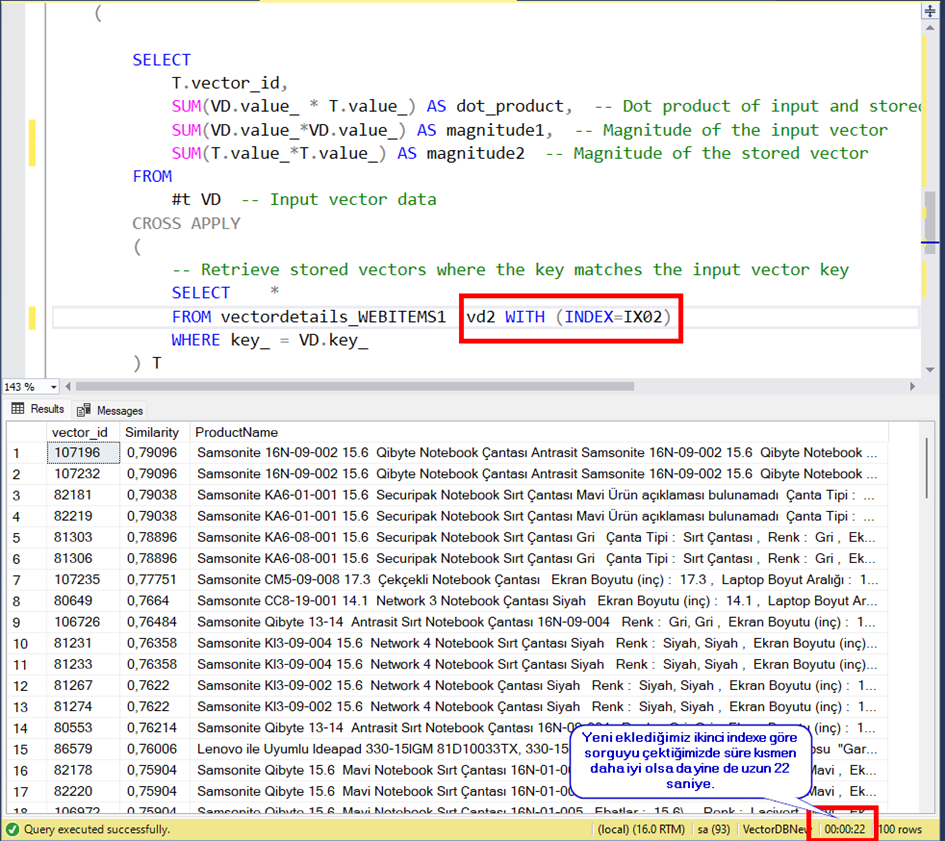
Görüldüğü gibi süre ilkine göre daha iyi değil. Bu süreler de kabul edilebilir süreler değil.
Burada iki şey yapılabilir.
Bu sorgudaki işlem türü columnstore index türüne daha uygun görünüyor.
Tablomuza bir clustered columnstore index ve birkaç index daha ekleyelim.
Hatta SQL Server 2022 ile birlikte gelen Ordered Clustered Columnstore Index ekleyelim.
CREATE CLUSTERED COLUMNSTORE INDEX [CCIX1] ON [dbo].[vectordetails_WEBITEMS]
Order(Vector_id)WITH ( DROP_EXISTING = on, COMPRESSION_DELAY = 0, DATA_COMPRESSION = COLUMNSTORE,
maxdop=1
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX IX1 ON dbo.vectordetails_WEBITEMS
(key_,vector_id)
INCLUDE(value_)
Şimdi süre 3 saniyeye kadar düştü.
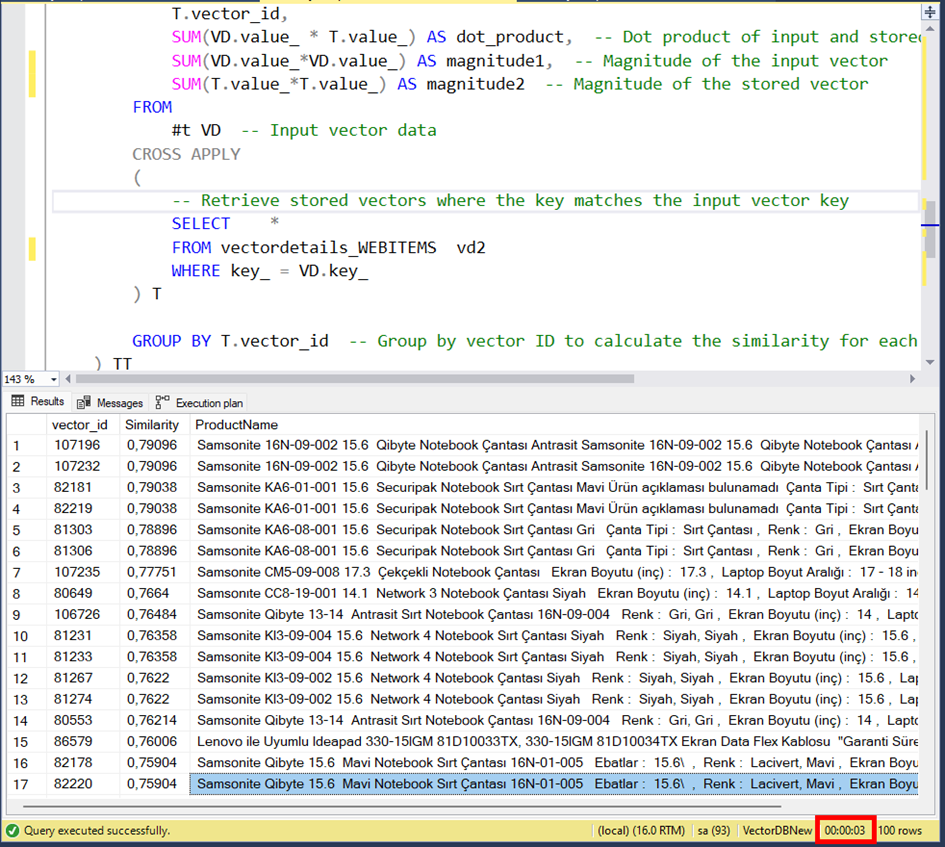
Bu sorguyu daha hızlandırmak için bir işlem daha kaldı.
Cosine distance hesabını hatırlarsak
1.DotProduct:Yani her iki vektörün aynı sıradaki elemanlarının birbiri ile çarpımı durumu sözkonusu.
2.Magnitude1, Magnitude2: Her iki vektörün tüm elemanlarının karesinin alınarak toplanması sonra tekrardan karekökünün alınması işlemi.
Burada 1. İşlemden kaçış yok çünkü tablodaki diğer vektörler ile ilişkili. Ama 2. İşlemi tek seferde hesaplatarak kaydedebiliriz ve bir daha hesaplamaya gerek kalmaz.
Bunun için tablomuza bir alan daha ekleyelim.
Alter Table vectordetails_WEBITEMS add valsqrt float
Update vectordetails_WEBITEMS set valsqrt=value_*value_
Şimdi de magnitude değerlerini hesaplamak için ayrı tablo daha ekleyelim.
CREATE TABLE vectorSummary(
id int IDENTITY(1,1),
vector_id int,
magnitude float ,
magnitudeSqrt float
)
Şimdi de vectorDetails_WEBITEMS tablosundan gruplayarak buraya atalım.
INSERT INTO vectorSummary_WEBITEMS
(vector_id,magnitude,magnitudeSqrt)
select vector_id,SUM(valsqrt) ,SQRT( SUM(valsqrt) )
FROM vectordetails_WEBITEMS
WHERE vector_id=@vectorId
GROUP BY vector_id
Son olarak bir de index oluşturalım.
CREATE NONCLUSTERED INDEX IX1 ON dbo.vectorSummary_WEBITEMS
(
vector_id ASC
)
INCLUDE(id,magnitude,magnitudeSqrt)
Şimdi de hesaplama sorgumuzu buna göre değiştirip çalıştıralım.
Evet şimdi görüldüğü gibi arama işlemi 1 saniye civarına düştü.
Vektör arama işlemi evrensel bir arama içerir.
Geleneksel metin tabanlı arama işlemlerinde siz arama yaparken metin tabanlı, kelime tabanlı bir karşılaştırma yaparsınız. Oysa vektör aramada anlam bütünlüğü olarak bir arama yaparsınız. Metin tabanlı aramalarda örneğin Türkçe bir veri seti içinde İngilizce bir arama yapamazsınız. Ya da arama öncesi İngilizce metni translate etmeniz gerekir.
Ama vektör tabanlı arama biraz beden dili gibi evrenseldir.
Yani “ben laptop çantası arıyorum” demek ile “I am looking for laptop pack” cümleleri birbirine çok yakındır.
Bu şekilde deneyebiliriz.
Özet ve Sonuç
Bu makalede On Prem SQL Server 2022 üzerinde bir vektör arama işleminin nasıl yapılacağı aşama aşama anlatılmıştır.
Mevcut durumda SQL Server 2022 üzerinde on prem olarak vektör arama özelliği bulunmadığı için tarafımdan TSQL ile yazılan algoritma ile arama yapılmıştır.
Vektöre çevirme işleminde “all-mpnet-base-v2” modeli kullanılmış olup 768 elemanlık vektörler oluşturulmuştur.
100.000 satırlık bir tabloda vektörler satırlara dönüştürülerek bir tabloda saklanmış olup, bu tablonun satır sayısı 82.937.856 (yaklaşık 83 milyon)
Bu tablo üzerinde performanslı arama yapmak için SQL Server 2022 ile birlikte gelen Ordered Clustered Columnstore Index kullanılmıştır.
Arama performans sonuçları şu şekildedir.
-100 bin satır üzerinde cosine distance fonksiyonu ile arama:12 saat
-100 bin satır üzerinde vektör elemanlarını satırlaştırarak primary key üzerinden arama:15 sn
-100 bin satır üzerinde vektör elemanlarını satırlaştırarak Ordered Clustered Columnstore index üzerinde arama:1 sn.
Genel Değerlendirme
Vektör arama kendi başına arama için tam yeterli olmamakla birlikte, yeni bir arama yaklaşımı olması niteliği ile ve dilden bağımsız anlam bütünlüğü araması ile çok farklı bir bakış açısı getirmektedir.
Öznitelik çıkarma ya da text arama ile birleştirildiğinde oldukça başarılı sonuçlar çıkarabilecektir.
Sistem performansını daha da arttırabilmek adına Clustered Columnstore Index üzerinde partitioning denenebilir.
Beğendiğinizi ümit ederim. Başka bir makalede görüşmek dileğiyle, sağlıcakla…








Çok açıklayıcı olmuş teşekkürler
Rica ederim. Beğenmenize sevindim.
Efsane makale olmuş hocam, eline sağlık.
Teşekkür ederim abi.