Exchange Server 2013 ile beraber gelen yeniliklerden biri olan Managed Availability, Exchange Server 2010 izleme özelliklerinin geliştirilmesi ve kullanıcı deneyimi odaklı olarak çalışan bir servistir. Temel anlamda Managed Availability, Exchange sistemlerinin izlenmesi ve gerekli görülmesi durumunda kurtarma aksiyonlarının alınmasını sağlar. Ancak buradaki odak noktası son kullanıcılar olup onların deneyimini en üst seviyede tutmak için tasarlanmıştır.

Bu yeni mimarinin ortaya çıkmasında Office 365 tecrübelerinden de yararlanılmıştır. Malum Microsoft uzun süredir Exchange Online + Office 365 tecrübesine sahip, dünya çapında milyonlarca müşteriye hizmet veren böylesi bir alt yapının izlenmesi ve bir takım aksiyonların alınması çok önemli olup bu tecrübelerini Exchange Server 2013 Managed Availability özelliğini geliştirirken kullandıklarını görüyoruz.
Bir diğer önemli konu ise artık sadece servisleri tek başına değil sunulan bir hizmet olarak son kullanıcıya olan etkisi ile beraber takip etmektedir. Yani kullanıcı odaklı bir izleme ve kurtarma sistemi sunulmaktadır.
Son olarak bundan önceki sürümlerdeki gibi izleme sadece bilgi verme değil tamamen edindiği bilgilere göre servisi kurtarma üzerine aksiyon alacak şekilde geliştirilmiştir.
Şimdi bu yeni özelliğin detaylarını beraber görelim.

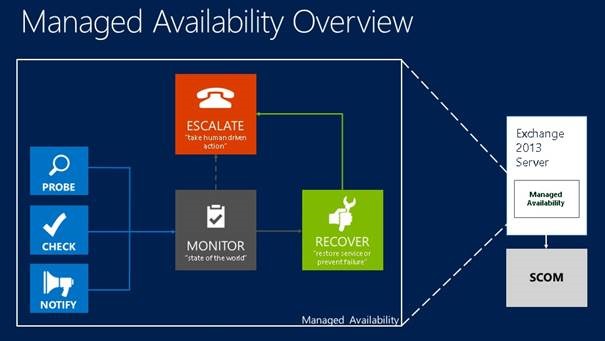
Managed Availability temel olarak 3 alt bileşenden oluşur.
Prob Engine – Sunucudan veri toplamaktan sorumludur. Aldığı veriler ile sürecin devamı olan Monitoring süreci işler.
Monitor – İzleme Bileşeni ise elde edilen verileri karşılaştırarak bir anormallik olup olmadığına karar verir.
Responder ( Recover ) – Monitor edilen verilerde bir sorun tespit edilir ise bu durumda Responder devreye girer ve sırası ile servisi kurtarmak için aksiyon alır;
Application Pool Restart
Services Restart
Server Restart
Eğer hala sorun devam ediyor ise sunucuyu istek almayacak şekilde kapatır.
Eğer bunlar sorunu çözmez ise loglarda bu bize bilgi olarak sunulur.
Bundan önceki mimaride her sunucuda çalışan SCOM agentları verileri merkezi SCOM sunucusuna gönderiyor, veriler burada toplanıyor, işleniyor ve sonuçta sorun olup olmadığı noktasında bilgilendirme yapılıyordu, bu yeni mimaride ise sistem farklı. Bunun en büyük nedeni eski mimaride eğer yapınız büyük ve karmaşık ise sorunların tespit edilmesi zaman alabilmekteydi.
Bu yeni mimaride ise her bir sunucu SCOM tarafına bir bilgi göndermeden önce kendi ölçümlerini yapıyor, bunları inceliyor gerekli ise aksiyon alıyor ve son noktada yöneticiye bilgi veriyor.
Şimdi bu alt bileşenleri biraz daha detaylı inceleyelim.
Probes
Probes, Exchange 2010’ dan hatırlayacağınız testcmd komutları gibi sentetik işlemler üzerine inşa edilmiştir (synthetic transactions )
Check, pasif bir izleme mekanizması olup gerçek ortam verilerini denetler.
Notify, Probe kontrollerinden bağımsız çalışabilir, sorun olur olmaz harekete geçer. Örneğin Exchange Server’ ın kullandığı sertifika süreci bitmesi bir uyarı olup bunu hemen yöneticiye bildirir.
Bir sonraki adım olan izleme ise öncelikle Probe tarafından toplanan veriler ile beslenir. Birden çok probe bir tek monitor’ e veri aktarabilir. Monitor tarafında bu veriler yorumlanır. Sonuç son derece basittir, sağlıklı veya sağlıksız J

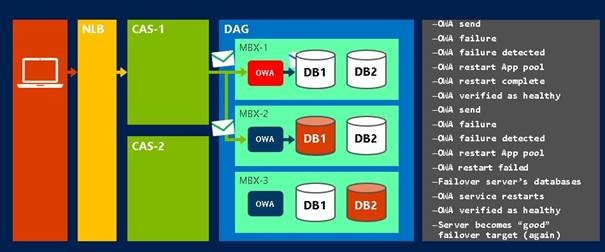
Yukarıda örnek bir senaryo var. Senaryodan anlayacağınız gibi amaç tamamen son kullanıcı deneyimi. Yukarıdaki şekile bakınca 4 farklı kontrol olduğunu görüyoruz. İlk kontrol posta kutusunun kendi kendini kontrol ettiği işlemdir. Bu Probe’ un amacı yerel protokol veya arabirim’ in veri tabanına erişilebilirliğini denetler. İkinci kontrol ise protokolün kendi kendini kontrol ettiği adımdır. Bu adımda yerel protokol’ ün posta kutusu sunucusu üzerinde çalışıp çalışmadığını kontrol eder. Üçüncü kontrol ise proxy’ nin kendi kendini kontrol ettiği adımdır. Proxy özelliğinin protokol üzerinde doğru olarak çalıştığının kontrolüdür. Bu kontrol Client Access üzerinde çalışır. Dördüncü kontrol ise her şeyi baştan sonra kontrol etme adımıdır. Bu sayede aslında gerçek bir kullanıcı deneyimi test edilmiş olur. Bu kontrollerin hepsi farklı zamanlarda çalışır.
Bu kontrollerin farklı zamanda çalışmasının yanında bir birinden bağımsız çalıştığı için alacağımız sonuçlar da ona göre değerlendirilir. Yani burada çok katmanlı bir kontrol söz konusudur. Örneğin yukarıdaki kontrollerden örnekleme yapmak gerekir ise mailbox self Test ve Protocol Self Test başarısız olmasına rağmen diğer iki test başarılı ise bu Store hizmetinin çalışmadığı anlamına gelmez. Bu o mailbox sunucusu üzerinde protokolün çalışmadığını gösterir. Veya yine yukarıdaki probe’lara göre örneklemeye devam edersek, bu sefer protocol self test çalışıyor mailbox self test ise çalışmıyorsa bu storage seviyesinde bir sorun olduğunu veya mailbox database’ in offline olduğunu gösterir. Örneğin OWA için konuşursak, Mailbox Self Test çalışmıyor, Protocol Self Test çalışıyor ise alarm gecikecektir, ancak her ikisi de çalışmaz ise anında alarm üretilir.
Responder
Responder, hatırlayacağınız gibi monitor tarafından sorun olduğuna dair bir bilgilendirme gelmesi halinde aksiyon alır. Birkaç çeşit responder olup aşağıdaki gibifir;
Restart Responder Servisi yeniden başlatır
Reset AppPool Responder IIS Application Pool Recycle dediğimi işlemi yapar yani pool’ u resetler
Failover Responder Sorunlu olan Mailbox sunucusunu servis dışı bırakır
Bugcheck Responder Sunucu da bug kontrolü başlatır
Offline Responder Sunucuyu devre dışı yapmak için protokolleri durdurur
Online Responder Sunucuyu tekrar devreye almak için protokolleri başlatır.
Escalate Responder Sorunu iletir
Specialized Component Responder
Offline Responder, CAS sunucusu üzerinde kullanılan protokolleri kaldırmak için kullanılır. Bu responder load balancer-agnostic olarak tasarlanmıştur. Bu responder tetiklendiği zaman protokoller kaldırıldığı için CAS sunucu önündeki Load Balancer sağlık kontrolü için bu sunucuya geldiğinde bu sunucu cevap vermeyecek, NLB[HU1] [HU2] cihazı da bu sunucuyu havuzdan çıkaracaktır. Bunun tam tersi ise Online responder olup bu da tekrar sunucuyu devreye almak için kullanılır. Aslında bu özellik “Set-ServerComponentState” komut seti ile biz sistem yöneticileri tarafından CAS sunucularını bakım moduna almak için kullanılır.

Yukarıda örnek bir senaryo var. Kullanıcıdan gelen OWA isteğinde hata alınması durumunda responder devreye giriyor ve App Pool için reset komutu gönderiyor, sistem düzeliyor, ancak tekrar owa isteği yapıldığında bu sefer responder’ ın yolladığı reset komutu çalışmadığı için veri tabanı Failover ile diğer bir mailbox sunucusuna aktarılır, owa servisi restart edilir ve owa sağlıklı çalıştığı görüldüğünde hizmet vermeye devam eder.
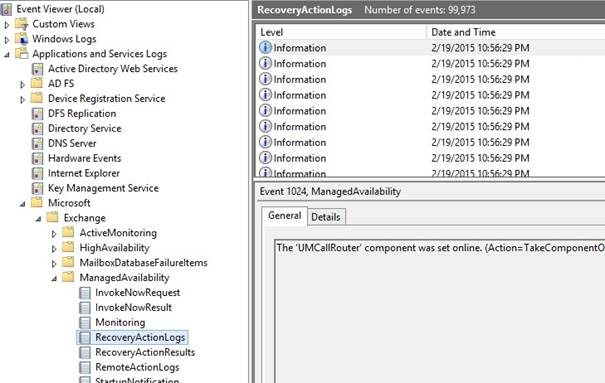
Bu tür aksiyonları aşağıdaki gibi olay günlüklerinden takip edebilirsiniz

Escalate responder çalıştığı zaman Exchange Server 2013 Management Pack’ in tanıyabileceği Windows Event oluşturulur. Bu alıştığımız normal bir olay değildir. Yani OWA’ nın çalışmadığı veya IO problemi uyarısı gibi değildir. Arızalı yada arızalı değildir sorununu açığa çıkaran bir Exchange olayıdır. Özetle sorun büyüyor ve devam ediyor ise Managed Availability olaya sistem yöneticisinin de müdahil olmasını sağlamayı amaçlıyordur.
Responder’lar alacakları aksiyonlar ile tüm servisleri tehlikeye sokmaması için bunlara da throttling uygulanabilir.
Bazı Responder’ lar DAG veya load balanced CAS havuzu içerisindeki sunucuları minimum sayıda hesaba katarlar.
Bazı Responder’ lar çalışma arasındaki süreleri hesaba katarlar.
Bazı Responder’ lar başlatılmış responder’ lar arasındaki sıklığı hesaba katarlar.
Bazı Responder’ lar ise yukarıda belirtilen kombinasyonların bazılarını kullanırlar.
Kurtarma Sıralaması
İzleme işleminin kesintiye uğrayan responder için tür ve zaman bilgisine sahip olması çok önemlidir. Bu sayede izleme yani Monitoring işlemi Recovery Sequance – kurtarma sıralamasını belirler. Örneğin OWA protokolü için prob sorunlu olarak alındı. Bu durumda o andaki zaman kaydedilir. Bu ana T diyeceğiz. İzleme kurtarma adımları oluşturmaya başlar. Bu yol haritası, kurtarma adımlarının zaman aralıklarının belirlenmesidir. Mailbox server üzerinde OWA protokol monitor’ ün kurtarma sıralaması aşağıdaki gibi olacaktır.

1 – T anını sıfır olarak kabul eder ise Reset AppPool Responder çalıştırılı ve IIS application pool recyce edilir. Yani bu hemen yapılır.
2 – T=5 dakika ise izleme için durum hala düzgün çalışmıyor ise, Failover responder devreye girer ve ver tabanları bir başka mailbox sunucusuna taşınır.
3 – T=8 dakika ise izleme için durum hala düzgün çalışmıyor ise, Bugcheck responder başlar ve suncu zorla yeniden başlatılmaya çalışılır.
4 – T=15 dakik ve izleme için durum hala düzgün çalışmıyor ise, Escalate responder başlatılır.
İzleme için sistem düzgün çalışıyor konumuna döndüğünde recovery sequence sürecide ( kurtarma adımları – sıralaması) durur.
Şimdi Managed Availability başlığı altındaki diğer bir konu olan Health Mailbox konusuna geçelim.
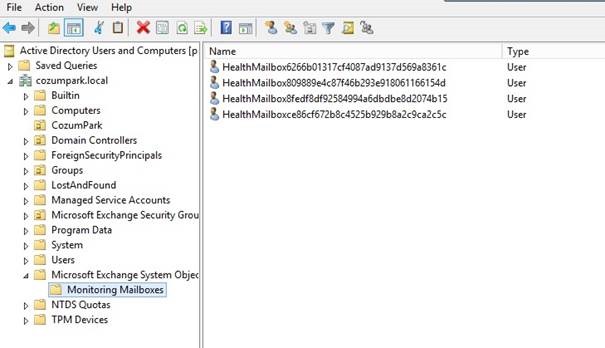
Exchange Server 2013 ile beraber hayatımıza giren yeniliklerden birisi de Health Mailbox kavramıdır. Aslında geniş kapsamda Managed Availability konusu içerisinde olan Health Mailbox , temel olarak posta kutularının izlenmesinden sorumlu posta kutularıdır. Aşağıdaki komut yardımı ile hemen bunları görelim
Get-Mailbox – Monitoring

Burada sizler farklı sayıda HM görebilirsiniz, bunun temel nedeni Exchange Server 2013 her bir mailboxdatabase için iki adet HM açar. Bunlardan biri Public Folder Health Check, diğeri ise Site Mailbox Health Check işleminden sorumludur. Bu posta kutuları kullanılarak Exchange server her 5 dakikada bir mail alışverişi yaparak sistemi kontrol eder ve eğer bir hata olur ise Managed Availability süreci işletilir.
Exchange üzerindeki her posta kutusu için AD üzerinde bir kullanıcı tanımlanır ve tabiki bu posta kutuları içinde benzer şekilde kullanıcı tanımları yapılmıştır. Bunları aşağıdaki yoldan görüntüleyebilirsiniz.

Bu kullanıcı hesapları üzerinde değişiklik yapmamanız önerilmektedir. Ancak bir sorun yaşamanız durumunda posta kutularını ve kullanıcıları silip Mailbox sunucusu üzerindeki Microsoft Exchange Health Manager servisini yeniden başlatırsanız kullanıcı ve posta kutularının yeniden oluşacağını göreceksiniz. Ancak bu durumun istisnası ilgili OU yuda bir şekilde silmiş veya kurulum sırasında oluşmamış ise bu durumda mevcut kurulum dosyanız ile ( yani kullandığınız sürüm ile aynı olmasına dikkat edin)
Setup.exe /preparead /Iacceptexchangeserverlicenseterms
Komutunu çalıştırın. Bu AD tarafındaki tüm gereksinimleri tekrar düzenleyecektir. Bu komut mevut sisteminizin de çalışmasını etkilemez.
Burada Health Mailbox ile ilgili ek bir bilgi vermek istiyorum. Eğer Exchange Server 2013 yapınızda Journal kullanacaksanız mutlaka bu sağlık kontrolü yapan ve her 5dk da bir gönderilen mailleri journal içine almayın.
Özetle Health Mailbox kullanıcısının AD üzerindeki Custom Attribute için bir değer veriyor, sonra dinamik bir dağıtım grubu oluşturuyor, ama filtreye bu öz nitelik açıklamasına sahip posta kutularını hariç tutmasını söylüyor ve son olarak journal rule için bu grubu kullanarak tüm mailleri topluyor ancak sağlık kontrolü için atılan mailler hariç.
Yine bir diğer konu ise eğer retention policy kullanıyorsanız bu policy için Health posta kutularını hariç tutun.
Eğer detay bilgi öğrenmek isterseniz bu konuda da aşağıdaki makaleyi önerebilirim
Şimdi ise bir diğer başlığımız olan Health Determination (Durum Belirleme) konusuna geldik.
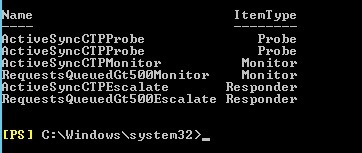
Exchange Server mimarisindeki aynı veya benzer bileşenlere bağlı monitörler bir health set olarak gruplanırlar. Bu grubun durumu içerisindeki en zayıf monitörün durumuna eşittir. Bu health set içerisindeki monitörler aşağıdaki komut yardımı ile görüntüleyebilirsiniz
Get-MonitoringItemIdentity -Identity HealthSet01 -Server ExchSrv01 | ft name,itemtype –AutoSize

Buraya tabiki bir Health Set ismi girmeniz lazım. Aşağıdaki listede Exchange Server üzerindeki Health Setleri görebilirsiniz
ActiveSync
ActiveSync.Protocol
ActiveSync.Proxy
AD
Antimalware
AntiSpam
Autodiscover
Autodiscover.Protocol
Autodiscover.Proxy
Calendaring
CentralAdmin
Clustering
DAL
Datamining
DataProtection
DiskController
ECP
ECP.Proxy
Ediscovery.Protocol
EDS
EventAssistants
EWS
EWS.Protocol
EWS.Proxy
FfoQuarantine
FIPS
FrontendTransport
HDPhoto
HubTransport
IMAP.Protocol
MailboxMigration
MailboxSpace
MailboxTransport
MessageTracing
Monitoring
MRS
MSExchangeCertificateDeployment
Network
OAB
OAB.Proxy
Outlook
Outlook.Protocol
Outlook.Proxy
OWA
OWA.Protocol
OWA.Protocol.Dep
OWA.Proxy
POP.Protocol
ProcessIsolation
Provisioning
PublicFolders
PushNotifications.Protocol
RemoteMonitoring
RPS
RPS.Proxy
RWS.Proxy
Search
Security
SiteMailbox
Store
Transport
TransportSync
UM.CallRouter
UM.Protocol
UserThrottling
Bu health set’ ler daha kullanışlı olması için 4 ana grup altında toplanmaktadır.
Customer Touch Points
OWA ve benzeri son kullanıcı etkileşimlerini temsil eden servisleri izleyen monitörler içerir. Erişilebilirlik, hata ve gecikmeler en önemli saç ayağı olup servisin erişilebilir olması, gecikme yaşatmaması ve kullanıcının istediğini yapabiliyor olması gereklidir.

Service Components
Hizmet bileşenlerini izleyen monitörleri içerir ( Örneğin OAB generation)
Server Components
Sunucu fiziksel kaynaklarını izleyen monitörleri içerir (Örneğin Disk, bellek, Ram vb)
Dependency Availability
Sunucuların bağlı olduğu diğer servis – sunucuların izleyen monitörleri içerir ( Örneğin Active Directory, DNS ve benzeri)
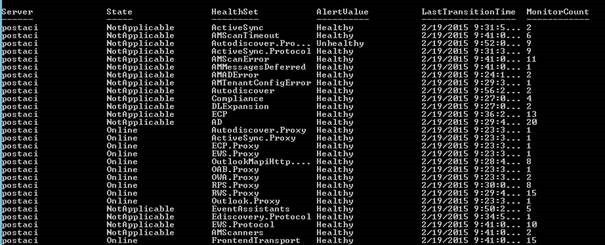
Daha geniş olarak sunucu sağlık durumuna bakmak için ise iki ayrı komut kullanabiliriz
Get-ServerHealth ve Get-HealthReport
Öncelikle Get-HealthReport ile sunucumuz ve servislerimiz hakkında özet bir bilgi alabiliriz
Get-HealthReport –Identity <ServerName>

Burada çıkabilecek sonuçlar aşağıdaki gibidir;
· Online
· Partially Online
· Offline
· Sidelined
· Functional
· Unavailable
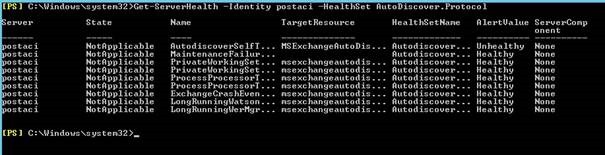
Yukarıda örneğin Autodiscover için “Unhealty” ibaresi var. Bunun detayına bakmak için ise
Get-ServerHealth –Identity <ServerName> –HealthSet Autodiscover.Protocol

Tam olarak detayları görmek için
Get-ServerHealth –Identity <ServerName> –HealthSet Autodiscover.Protocol | Format-Table –Wrap -Auto

Sorunun MSExchangeAutoDiscoverAppPool da olduğunu görüyoruz ve bunu bir recycle yapıyoruz.

Eğer sorun hala devam ediyor ise aşağıdaki komutu kullanıyoruz
Invoke-MonitoringProbe Autodiscover.Protocol\AutodiscoverSelfTestProbe -Server server1.contoso.com | Format-List
Eğer bunun sonucunda hata hala devam ediyor ise aşağıdaki makaleyi takip edebilirsiniz
Sadece sorunlu olan monitörleri listelemek için aşağıdaki komutu kullanabilirsiniz
Get-HealthReport -server postaci | where {$_.alertvalue -ne “healthy”} | ft –auto

Bunları ise loglardan takip edebilirsiniz.
Responder Throttling
Malum makalemizde Responder konusuna değinmiş ve bunların genel olarak alınan sağlıksız durum bilgisinden sonra tetiklenen aksiyonlar kümesi olduğunu görmüştük.
Monitor edilen verilerde bir sorun tespit edilir ise bu durumda Responder devreye girer ve sırası ile servisi kurtarmak için aksiyon alır;
Application Pool Restart
Services Restart
Server Restart
Eğer hala sorun devam ediyor ise sunucuyu istek almayacak şekilde kapatır.
Eğer bunlar sorunu çözmez ise loglarda bu bize bilgi olarak sunulur.
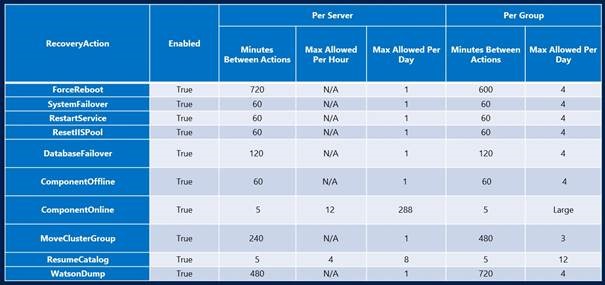
Bu aksiyonlar için Exchange Server 2013 CU2 öncesi koyduğumuz bir takım limitler CU2 ile beraber değişti. CU2 öncesi sadece sunucu başına limit koyabiliyorken şu anda organizasyon seviyesinde limitler koyabiliyoruz. Örneğin Server Restart responder için DAG üyesi olan sunucularda 60dk içerisinde maksimum 4 kez çalışmasını sağlayabiliyoruz.
Aşağıda bu konuda bir tablo paylaşıyorum

Şimdi ise Overrides
Konusuna gelelim
Malum sahip olduğunuz ortamda her zaman istenilen performans veya en sağlıklı durum için şartlar sağlanamayabilir, böyle durumlarda sistemin çalışmasına devam etmesi için mevcut değerler üzerinde bir takım değişikliklere gidilmesi gerekebilir. Biz bunlara Override diyoruz.
Bunu tüm ortam veya bir sunucu üzerinde yapabiliriz.
ServerMonitoringOverride
GlobalMonitoringOverride
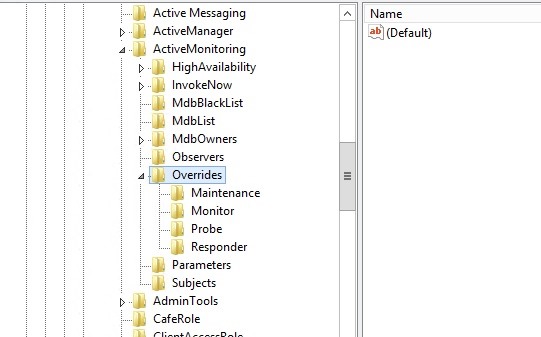
Tek bir sunucu için değişiklik yapmak istiyorsanız Exchange Server kurulumu ile beraber gelen ve 10dk da bir kontrol edilen aşağıdaki dizinde değişiklik yapabilir ve hemen aktif olması için servisi restart edebilirsiniz.
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\ExchangeServer\v15\ActiveMonitoring\Overrides

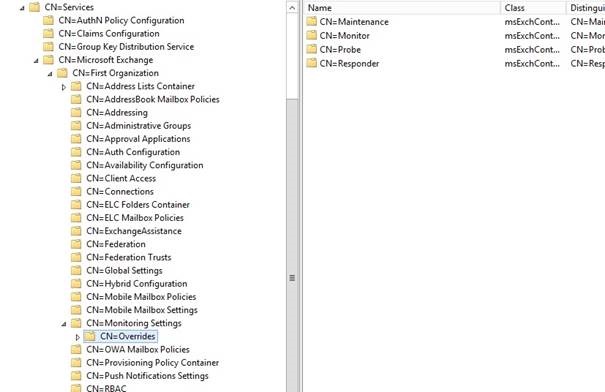
Tüm Exchange Sunucularına etki edecek olan ayar ise Active Directory içerisinde aşağıdaki yolda bulunur
CN=Overrides,CN=Monitoring Settings,CN=First Organization,CN=Microsoft Exchange,CN=Services,CN=Configuration,DC=cozumpark,DC=local

Yerel bir override eklemek için aşağıdaki gibi bir komut seti kullanıyoruz
Add-ServerMonitoringOverride -Server ServerName -Identity <ItemtoOverride> -ItemType <ItemType>
-PropertyName <PropertyName> -PropertyValue <Value> -Duration <DurationofOverride>
Örnek bir komut
Add-ServerMonitoringOverride -Server postaci -Identity FrontEndTransport\OnPremisesInboundProxy
-ItemType Probe -PropertyName ExtensionAttributes -PropertyValue '<ExtensionAttributes><WorkContext>
<SmtpServer>postaci.cozumpark.local</SmtpServer><Port>25</Port><HeloDomain>InboundProxyProbe</HeloDomain>
<MailFrom Username="[email protected]" />
<MailTo Select="All" Username="[email protected]" />
<Data AddAttributions="false">X-Exchange-Probe-Drop-Message:FrontEnd-CAT-250Subject:Inbound proxy probe</Data>
<ExpectedConnectionLostPoint>None</ExpectedConnectionLostPoint></WorkContext>
</ExtensionAttributes>' -Duration 45.00:00:00
OnPremisesInboundProxy için 45 günlük bir override eklemiş oldum.
Bu tarz oluşturmuş olduğunuz override kurallarını aşağıdaki komut ile görüntüleyebilirsiniz
Get-ServerMonitoringOverride -Server | Format-List
Silmek için ise
Remove-ServerMonitoringOverride -Server postaci -Identity FrontEndTransport\OnPremisesInboundProxy
-ItemType Probe -PropertyName ExtensionAttributes
Global bir override oluşturmak için ise aşağıdaki gibi bir komut kullanıyoruz
Add-GlobalMonitoringOverride -Identity <ItemtoOverride> –ItemType
<ItemType> -PropertyName <PropertytoOverride> -PropertyValue <NewPropertyValue>
Hatta bu komutu belirli bir Exchange sürümü için bile çalıştırabilirsiniz
Add-GlobalMonitoringOverride -Identity <ItemtoOverride> –ItemType
<ItemType> -PropertyName <PropertytoOverride> –PropertyValue
<NewPropertyValue> -ApplyVersion <ExchangeVersion> -Duration 45.00:00:00
Bununda takip etmek için
Get-GlobalMonitoringOverride
Silmek için
Remove-GlobalMonitoringOverride -Identity <ItemtoOverride>
-ItemType <ItemType> -PropertyName <OverriddenProperty>
Kaynak
Kaynak linkerin pek çoğu artık geçersiz olduğu için silinmiştir.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}