
Çin merkezli yapay zekâ girişimi DeepSeek, geliştirdiği DeepSeek-V3 modelini, rakiplerine kıyasla 11 kat daha az GPU hesaplama gücü kullanarak eğittiğini duyurdu. Bu yenilik, ABD’nin uyguladığı yapay zekâ çip ambargolarının etkisini azaltmaya yönelik etkileyici bir adım olarak değerlendiriliyor. Şirketin ileri düzey optimizasyon ve düşük seviyeli programlama teknikleri sayesinde bu başarıyı elde ettiği belirtiliyor.
DeepSeek, 671 milyar parametreye sahip DeepSeek-V3 modelini, 2.048 Nvidia H800 GPU kullanarak sadece iki ayda eğitmeyi başardı. Bu, toplamda 2,8 milyon GPU saati anlamına geliyor. Karşılaştırıldığında, Meta’nın Llama 3 modelini eğitmek için 16.384 Nvidia H100 GPU ile 30,8 milyon GPU saati harcadığı biliniyor.


Şirket, bu düşük hesaplama maliyetlerini gelişmiş pipeline algoritmaları, optimize edilmiş iletişim çerçevesi ve FP8 düşük hassasiyetli hesaplama gibi tekniklerle mümkün kıldığını belirtiyor. DualPipe adlı algoritma, işlem ve iletişim süreçlerini eş zamanlı yürüterek darboğazları en aza indiriyor. Bu yaklaşım, özellikle MoE (Mixture-of-Experts) mimarisinde kullanılan çapraz düğüm paralelliğinde büyük bir verimlilik sağlıyor.
DeepSeek ayrıca, her bir token’in maksimum dört düğümle iletişim kurmasını sağlayarak ağ trafiğini azalttı. Bu teknik, işlem ve iletişim süreçlerinin daha etkili bir şekilde örtüşmesini sağladı. Ayrıca, FP8 karışık hassasiyet çerçevesi kullanılarak bellek kullanımı azaltıldı ve hesaplama hızlandırıldı. Hassasiyet gerektiren katmanlarda ise BF16 ve FP32 gibi daha yüksek hassasiyet formatları korundu.
DeepSeek-V3’ün Performansı
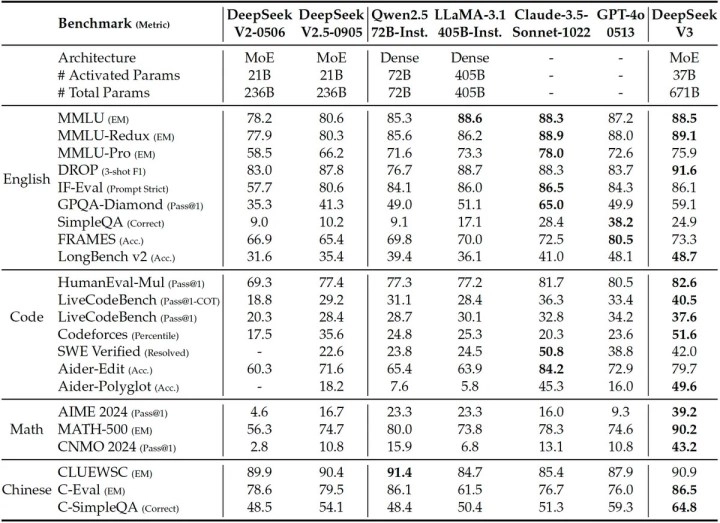
DeepSeek’e göre, DeepSeek-V3 modeli, GPT-4x, Claude-3.5-Sonnet ve Llama-3.1 gibi önde gelen yapay zekâ modelleriyle rekabet edebilecek düzeyde. Şirket, modelin ağırlıklarını ve kaynak kodunu açık kaynak olarak yayımlayarak üçüncü taraf testlerinin yapılmasını teşvik ediyor.
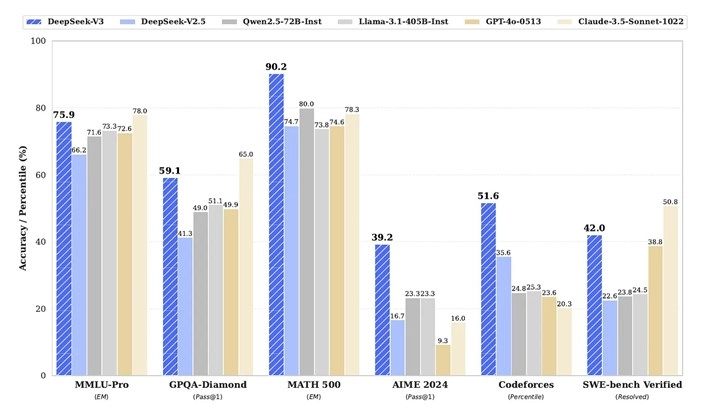
DeepSeek’in modeli, parametre sayısı veya muhakeme yetenekleri açısından bazı frontier modellerin gerisinde kalabilir. Ancak bu başarı, sınırlı kaynaklarla ileri düzey bir dil modeli eğitmenin mümkün olduğunu gösteriyor.
DeepSeek ekibi, DeepSeek-V3 modelinin kullanımında bazı zorluklar olduğunu kabul ediyor. Modelin etkili bir şekilde uygulanabilmesi için gelişmiş donanım ve kapsamlı bir dağıtım stratejisi gerekiyor. Bu durum, küçük ölçekli ekipler için maliyet ve altyapı açısından zorlayıcı olabilir. Yine de DeepSeek’in optimizasyon çalışmaları, yapay zekâ modellerinin gelecekte daha verimli ve maliyet-etkin bir şekilde eğitilmesine yönelik umut verici bir yol haritası sunuyor.








