
Metni Videoya Dönüştürme: Azure OpenAI Yapay Zeka, Bilişsel Hizmetler ve Anlamsal işlemler (Python)
Azure ve OpenAI dünyasına bir yolculuğa çıkıyoruz! Bu yolculukta Azure’un güçlü yapay zeka özelliklerini kullanarak metni videoya nasıl dönüştürebileceğimizi keşfedeceğiz Semantic Kernel ile uygulama akışımızı oluşturup ilerleyeceğiz
Semantic Kernel, metnin anlamını daha ince bir şekilde anlamamızı ve değiştirmemizi sağlayan güçlü bir araçtır. Semantic Kernel’ı kullanarak daha karmaşık iş akışları oluşturabilir ve metinden videoya dönüştürme sürecimizden daha anlamlı ve net sonuçlar elde edebiliriz yani metinden yüksek kaliteli video içeriği oluşturmaya odaklanmamızı sağlayacağız.
İlk olarak (Environment File) dosyalarımızı oluşturmak ile başlayacağız
ben adını env.dev olarak veriyorum ve içeriğini bu şekilde hazırladım API keylerini girip aynı içeriği kullanabilirsiniz
AZURE_OPENAI_DEPLOYMENT_NAME="<AzureOpenAI Deployment Name>"
AZURE_OPENAI_ENDPOINT="<Azure OpenAI Endpoint>"
AZURE_OPENAI_API_KEY="<Azure Open AI Key>"
SPEECH_KEY="<Azure Cognitive Service Key>"
SPEECH_REGION="<Azure Cognitive Service Region>"
DALLE_API_BASE="<Azure DALL-E2 API base url>"
DALLE_API_KEY="<Azure DALL-E2 API key>"
DALLE_API_VERSION="<Azure DALL-E2 API Version>"AzureOpenAI ve DALL-E’yi aynı kaynakta kullanıyorsanız AZURE_OPENAI_ENDPOINT ve AZURE_OPENAI_API_KEY, DALLE_API_BASE ve DALLE_API_KEY için aynı olacaktır dikkat etmeliyiz.
buradaki değişkenleride hızlıca açıklayım size
Değişkenlerin açıklaması:
Yukarıdaki kod dotenv formatında yazılmış bir yapılandırma dosyasıdır. Çeşitli API’leri ve hizmetleri yapılandırmak için kullanılan çeşitli ortam değişkenlerini içerir.
İlk üç ortam değişkeni OpenAI API ile ilgilidir. AZURE_OPENAI_DEPLOYMENT_NAME değişkeni, GPT Turbo Tamamlama modelini barındırmak için kullanılan dağıtımın adını belirtir. AZURE_OPENAI_ENDPOINT değişkeni, OpenAI API’sinin uç nokta URL’sini belirtir. Son olarak AZURE_OPENAI_API_KEY değişkeni, OpenAI API’sine yönelik isteklerin kimliğini doğrulamak için kullanılan API anahtarını içerir.
Sonraki iki ortam değişkeni Azure Konuşma Hizmetleri API’si ile ilgilidir. SPEECH_KEY değişkeni, Konuşma Hizmetleri API’sine yönelik isteklerin kimliğini doğrulamak için kullanılan API anahtarını içerir. SPEECH_REGION değişkeni, Konuşma Hizmetleri API’sinin barındırıldığı bölgeyi belirtir.
Son üç ortam değişkeni, başka bir OpenAI API’si olan DALL-E API ile ilgilidir. DALLE_API_BASE değişkeni, DALL-E API’sinin temel URL’sini belirtir. DALLE_API_KEY değişkeni, DALL-E API’sine yönelik isteklerin kimliğini doğrulamak için kullanılan API anahtarını içerir. Son olarak DALLE_API_VERSION değişkeni, kullanılan DALL-E API’nin sürümünü belirtir.
Genel olarak bu yapılandırma dosyası, uygulama tarafından kullanılan hassas bilgileri ve yapılandırma ayarlarını depolamak için kullanılır. Uygulama, ortam değişkenlerini kullanarak bu bilgilere, kaynak koduna sabit kodlamaya gerek kalmadan kolayca erişebilir.
Bu kodun okunabilirliğini artırmak için ilgili ortam değişkenlerini bir arada gruplamak ve her değişkenin ne için kullanıldığını açıklayan yorumlar eklemek faydalı olabilir. Ayrıca dosyanın doğru biçimlendirildiğinden ve sözdizimi hatası olmadığından emin olmak için dotenv-linter gibi bir araç kullanmak faydalı olabilir ben biraz hakim olduğum için tercih etmedim.
Sıra Geldi Klasör yapısını oluşturmaya
Bu uygulama için bir klasör yapısı önereceğim.
Bu uygulama için 4 klasör oluşturdum.
Audio/Ses için : Azure Konuşma Hizmeti tarafından oluşturulan sesleri tutmak için klasör
images/Görüntüler için: DALL-E API çağrıları tarafından oluşturulan görüntülerimi tutmak için klasör
myPlugins/ekletiler için: Bu uygulama için tüm eklentilerimi çalıştırdığım klasör.
Video: Bu uygulamadaki son Videoları depolamak için klasör.
Klasörlerimizi ayarladıktan sonra ki adıma geçelim
Eklentileri oluşturma adımları
Semantic core eklentileri, YZ sistemlerinin yeteneklerini geliştirmek için geliştiriciler tarafından titizlikle hazırlanmış modüler işlevler olarak hizmet eder. Bu çok yönlü birimler yapay zeka işlevlerini kapsar ve Semantic Kernel mimarisinin temel bileşenlerini oluşturur. ChatGPT, Bing ve Microsoft 365 içindeki eklentilerle sorunsuz bir şekilde etkileşime girerek uyumlu bir yapay zeka inovasyon ekosistemini teşvik ederler.
Bu eklentiler iki farklı işlev türüyle ayırt edilir:
Semantic Functions: Bunlar, bağlamsal değişkenlerle iç içe geçmiş dinamik istemlerdir. Öncelikle metinsel girdileri ve çıktıları ele alırlar ve yapay zeka sistemiyle incelikli etkileşimler için kanallar olarak işlev görürler.
Neative Functions:: Bu işlevler, arama sonuçlarının ayrılmaz bir parçası olmakla birlikte, eklenti repertuarına önemli ölçüde katkıda bulunurlar.
Ayrıca Semantik Çekirdek, çeşitli programlama dillerine göre uyarlanmış bir dizi önceden tasarlanmış eklentiye sahiptir. Genellikle Çekirdek eklentiler olarak adlandırılan bu temel eklentiler, Semantik Çekirdek’in kapsamlı faydasını örneklendirmektedir. Şu anda Semantic Kernel çerçevesinde erişilebilir olan bu Çekirdek eklentilerden bazıları şunlardır:
- ConversationSummarySkill: Diyalogları kısa ve öz bir şekilde özetleme.
- FileIOSkill: Okuma ve yazma için dosya sistemi etkileşimlerini kolaylaştırma.
- HttpSkill: Sorunsuz API çağrılarını etkinleştirme.
- MathSkill: Matematiksel hesaplamaların güçlendirilmesi.
- TextMemorySkill: Metni bellekte saklama ve bellekten alma.
- TextSkill: Dizelerinin deterministik manipülasyonunu sağlamak.(bu biraz karışık bir kavram)
- TimeSkill: Günün saati ve ilgili ayrıntılar dahil olmak üzere zamansal içgörüler elde etmek
- WaitSkill: Tanımlanan aralıklar için yürütmeyi geçici olarak askıya alma.
Bu eklentiler sayesinde extra argumanlar için hiç zaman kaybetmeden AI uygulamamızı devreya alabiliriz düşünzenize bunu azure dışında yaptığınızı ? hepsini tek tek yazmak çalıştırmak entegre etmek büyük zaman emek harcamanıza sebep olur ve hepsini kendimiz yapmamız pek mümkün değil AI dünyasını henüz yeni yeni tecrübe ediyoruz bu yüzden AZURE AI servislerini tıkır tıkır işletmek bize hız ve daha esnek davranma imkanı tanıyor.
Bu uygulamada tüm eklentilerimizi sıfırdan oluşturacağız. Semantik fonksiyon ve Yerel Fonksiyonların bir kombinasyonu olacaktır. Aşağıdaki tabloda eklentiler hakkında detaylar bu şekilde.
| Plugin | Function | Type | Description |
| summarizePlugin | NA | Semantic | Generating the Summary of the content |
| audioPlugin | create_audio_file | Native | Generate Audio file |
| promptPlugin | NA | Semantic | Generate DALL-E2 image prompts |
| imagePlugin | create_image_files | Native | Generate Image files |
| videoPlugin | create_video_files | Native | Generate Video file |

Hadi ilk (plugin) eklentimizi oluşturalım
Summarize Eklentisi için myPlugins klasörü içinde SummaryPlugin adında yeni bir klasör oluşturun.
Orada iki dosya daha oluşturun:
- config.json
- skprompt.txt
Config.json’a aşağıdaki içeriği ekleyin:
{
"schema": 1,
"description": "Summarize the content",
"type": "completion",
"completion": {
"max_tokens": 1000,
"temperature": 0,
"top_p": 0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "input",
"description": "Summarize the content",
"defaultValue": ""
}
]
}
}Skprompt.txt’de:
{{$input}}
Summarize the content in less than 100 words.
Summary: Ses Eklentisi
Ses Eklentisi için myPlugins klasörü içerisinde audioPlugin adında yeni bir klasör oluşturun.
audioPlugin.py adında yeni bir dosya oluşturun
import azure.cognitiveservices.speech as speechsdk
from semantic_kernel.skill_definition import (
sk_function,
sk_function_context_parameter,
)
from semantic_kernel.orchestration.sk_context import SKContext
class AudioPlugin:
@SK_function(
description="Creates a audio file with the given content",
name="create_audio_file",
input_description="The content to be converted to audio",
)
@SK_function_context_parameter(
name="content",
description="The content to be converted to audio",
)
@SK_function_context_parameter(
name="speech_key",
description="speech_key",
)
@SK_function_context_parameter(
name="speech_region",
description="speech_region",
)
def create_audio_file(self, context: SKContext):
speech_config = speechsdk.SpeechConfig(subscription=context["speech_key"], region=context["speech_region"])
content = context["content"]
filename = "Audio/audio.mp4"
audio_config = speechsdk.AudioConfig(filename=filename)
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
result = speech_synthesizer.speak_text_async(content).get()
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print(f"Audio saved to {filename}")
else:
print(f"Error: {result.error_details}")
print("Audio file created.....")
Kod hakkında biraz detay vereyim
Yukarıdaki kod, create_audio_file adı verilen tek bir yöntemi içeren AudioPlugin adlı bir Python sınıfını tanımlar. Bu yöntem, işlevin giriş parametrelerini tanımlayan birkaç sk_function_context_parameter dekoratörüyle donatılmıştır.
create_audio_file yöntemi, SKContext sınıfının bir örneği olan context adı verilen tek bir giriş parametresini alır. Bu sınıf başka bir modülde tanımlanır ve uygulamanın farklı bölümleri arasında bağlam bilgilerinin aktarılmasına yönelik bir yol sağlar.
Create_audio_file yönteminde gerçekleşen ilk şey, bağlam nesnesindeki konuşma_key ve konuşma_region parametreleri kullanılarak bir SpeechConfig nesnesinin oluşturulmasıdır. Bu nesne, metni sese dönüştürmek için kullanılacak konuşma sentezi hizmetini yapılandırmak için kullanılır.
Daha sonra bağlam nesnesinden içerik parametresi alınır ve bir değişkende saklanır. Bu içerik bir sonraki adımda sese dönüştürülecek.
Bundan sonra çıktı ses dosyası için bir dosya adı belirtilir. Bu dosya audio.mp4 adıyla Ses dizinine kaydedilecektir.
Daha sonra önceki adımda belirtilen dosya adı kullanılarak bir AudioConfig nesnesi oluşturulur. Bu nesne, konuşma sentezi hizmeti için ses çıkış ayarlarını yapılandırmak için kullanılır.
Son olarak SpeechConfig ve AudioConfig nesneleri kullanılarak bir SpeechSynthesizer nesnesi oluşturulur. Bu nesne, giriş metninden ses sentezlemek için kullanılır. Speaking_text_async yöntemi, giriş olarak content parametresiyle SpeechSynthesizer nesnesinde çağrılır. Daha sonra ses sentezinin tamamlanmasını beklemek için bu yöntemin sonucu üzerine get yöntemi çağrılır.
Ses sentezi başarılı olursa, ortaya çıkan ses dosyası belirtilen dosya adına kaydedilir ve konsola ses dosyasının oluşturulduğunu belirten bir mesaj yazdırılır. Ses sentezi işlemi sırasında bir hata oluşursa bunun yerine konsola bir hata mesajı yazdırılır.
Genel olarak bu kod, Azure Konuşma Hizmetleri API’sini kullanarak metinden ses dosyaları oluşturmak için kullanılabilecek bir sınıfı tanımlar. Gerekli konfigürasyon bilgilerini iletmek için SKContext sınıfını kullanarak bu sınıf, uygulamanın diğer bölümlerine kolayca entegre edilebilir.
Sıra geldi En önemi ekletiye
Prompt Plugin
Prompt Plugin için myPlugins klasörü içerisinde PromptPlugin adında yeni bir klasör oluşturun.
Orada iki dosya daha oluşturalım:
- config.json
- skprompt.txt
Config.json’a aşağıdaki içeriği ekleyelim:
{
"schema": 1,
"description": "Create Dalle prompt ideas",
"type": "completion",
"completion": {
"max_tokens": 1000,
"temperature": 0.9,
"top_p": 0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0
},
"input": {
"parameters": [
{
"name": "input",
"description": "Create Dalle prompt ideas",
"defaultValue": ""
}
]
}
}Skprompt.txt’ de ekleme yapacağiz
create 10 dall-e image prompts ideas on the below content
{{$input}}
Prompts: Image Plugin için myPlugins klasörü içerisinde imagePlugin adında yeni bir klasör oluşturun.
imagePlugin.py adında yeni bir dosya oluşturun
import requests
import time
import urllib.request
from semantic_kernel.skill_definition import (
sk_function,
sk_function_context_parameter,
)
from semantic_kernel.orchestration.sk_context import SKContext
class ImagePlugin:
@SK_function(
description="Creates images with the given prompts",
name="create_image_files",
input_description="The content to be converted to images",
)
@SK_function_context_parameter(
name="prompts",
description="The content to be converted to images",
)
@SK_function_context_parameter(
name="api_base",
description="api_base",
)
@SK_function_context_parameter(
name="api_key",
description="api_key",
)
@SK_function_context_parameter(
name="api_version",
description="api_version",
)
def create_image_files(self, context: SKContext):
api_base = context["api_base"]
api_key = context["api_key"]
api_version = context["api_version"]
url = "{}dalle/text-to-image?api-version={}".format(api_base, api_version)
headers= { "api-key": api_key, "Content-Type": "application/json" }
images = []
counter = 0
image_list = []
for phrase in context["prompts"]:
print("Image for: ",phrase)
body = {
"caption": phrase ,
"resolution": "1024x1024"
}
submission = requests.post(url, headers=headers, json=body)
operation_location = submission.headers['Operation-Location']
retry_after = submission.headers['Retry-after']
status = ""
#while (status != "Succeeded"):
time.sleep(int(retry_after))
response = requests.get(operation_location, headers=headers)
status = response.json()['status']
#print(status)
if status == "Succeeded":
counter += 1
image_url = response.json()['result']['contentUrl']
filename = "Images/file" + str(counter) + ".jpg"
urllib.request.urlretrieve(image_url, filename)Bu koduda size açıklayayım
Kodun açıklaması:
Yukarıdaki kod, create_image_files adı verilen tek bir yöntemi içeren ImagePlugin adlı bir Python sınıfını tanımlar. Bu yöntem, işlevin giriş parametrelerini tanımlayan birkaç sk_function_context_parameter dekoratörüyle donatılmıştır.
create_image_files yöntemi, SKContext sınıfının bir örneği olan context adı verilen tek bir giriş parametresini alır. Bu sınıf başka bir modülde tanımlanır ve uygulamanın farklı bölümleri arasında bağlam bilgilerinin aktarılmasına yönelik bir yol sağlar.
create_image_files yönteminde, bağlam nesnesinden alınan değerler kullanılarak çeşitli değişkenler başlatılır. Bu değişkenler, görüntüleri oluşturmak için kullanılacak DALL-E API’sini yapılandırmak için kullanılan api_base, api_key ve api_version parametrelerini içerir.
Daha sonra, bağlam nesnesinin istem parametresindeki her bilgi istemi üzerinde yinelenen bir döngü başlatılır. Her bilgi istemi için, DALL-E API’sine, bilgi isteminin başlığı ve 1024×1024 çözünürlüğü ile birlikte bir POST isteği gönderilir. API’den gelen yanıt, görüntü oluşturma işleminin durumuna ilişkin URL’yi içeren bir Operasyon Konumu başlığını içerir.
Kod daha sonra, görüntü oluşturma işleminin durumunu kontrol etmek için Operasyon Konumu URL’sine bir GET isteği göndermeden önce yanıtın Yeniden Deneme başlığında belirtilen sayıda saniye bekler. Bu işlem işlemin durumu “Başarılı” olana kadar tekrarlanır.
Görüntü oluşturma işlemi başarılı olduğunda, ortaya çıkan görüntü yanıtta belirtilen contentUrl’den indirilir ve her görüntünün benzersiz bir dosya adına sahip olmasını sağlamak için bir sayaç içeren dosya adına sahip bir dosyaya kaydedilir.
Genel olarak bu kod, DALL-E API’sini kullanarak metinden görseller oluşturmak için kullanılabilecek bir sınıfı tanımlar. Gerekli konfigürasyon bilgilerini iletmek için SKContext sınıfını kullanarak bu sınıf, uygulamanın diğer bölümlerine kolayca entegre edilebilir.
Video Eklentisi
Video Eklentisi için myPlugins klasörü içerisinde videoPlugin adında yeni bir klasör oluşturalım.
videoPlugin.py adında yeni bir dosya oluşturun
from moviepy.editor import *
from semantic_kernel.skill_definition import (
sk_function
)
from semantic_kernel.orchestration.sk_context import SKContext
class VideoPlugin:
@SK_function(
description="Creates images with the given prompts",
name="create_video_file",
input_description="The content to be converted to images",
)
def create_video_file(self, context: SKContext):
images = []
for i in range(1,11):
images.append("Images/file" + str(i) + ".jpg")
audio = "Audio/audio.mp4"
output = "Video/video.mp4"
self.create_video(images, audio, output)
print("Video created.....")
def create_video(self,images, audio, output):
clips = [ImageClip(m).resize(height=1024).set_duration(3) for m in images]
concat_clip = concatenate_videoclips(clips, method="compose")
audio_clip = AudioFileClip(audio)
final_clip = concat_clip.set_audio(audio_clip)
final_clip.write_videofile(output, fps=20)Kodun açıklaması:
Yukarıdaki kod, create_video_file adı verilen tek bir yöntemi içeren VideoPlugin adlı bir Python sınıfını tanımlar. Bu yöntem, işlevi Semantic Kernel’de kullanılabilecek bir beceri olarak tanımlayan bir sk_function dekoratörüyle süslenmiştir.
create_video_file yöntemi, SKContext sınıfının bir örneği olan context adı verilen tek bir giriş parametresini alır. Bu sınıf başka bir modülde tanımlanır ve uygulamanın farklı bölümleri arasında bağlam bilgilerinin aktarılmasına yönelik bir yol sağlar.
Create_video_file yönteminde, görüntülerin, sesin ve çıkış videosunun dosya adlarıyla çeşitli değişkenler başlatılır. Images değişkeni, videoyu oluşturmak için kullanılacak görsellerin dosya adlarının bir listesidir. Ses değişkeni, videonun müziği olarak kullanılacak ses dosyasının dosya adıdır. Çıkış değişkeni, çıkış video dosyasının dosya adıdır.
Create_video yöntemi daha sonra girdi olarak görüntüler, ses ve çıktı değişkenleri ile çağrılır. Bu yöntem, giriş görüntülerinden ve sesten bir video oluşturmak için moviepy kitaplığını kullanır.
İlk olarak, girdi görüntülerinden ImageClip nesnelerinin bir listesi oluşturulur. Her klip 1024 piksel yüksekliğe yeniden boyutlandırılır ve 3 saniyelik bir süreye ayarlanır.
Daha sonra, klipleri tek bir video klipte birleştirmek için concatenate_videoclips işlevi kullanılır. Daha sonra set_audio yöntemi, giriş olarak giriş ses dosyasından oluşturulan bir AudioFileClip nesnesi ile birleştirilmiş klipte çağrılır.
Son olarak, ortaya çıkan klipte çıktı dosya adı ve girdi olarak saniyede 20 kare kare hızıyla write_videofile yöntemi çağrılır.
Video oluşturma başarılı olursa konsola videonun oluşturulduğunu belirten bir mesaj yazdırılır.
Genel olarak bu kod, moviepy kitaplığını kullanarak görüntülerden ve seslerden videolar oluşturmak için kullanılabilecek bir sınıfı tanımlar. Gerekli konfigürasyon bilgilerini iletmek için SKContext sınıfını kullanarak bu sınıf, uygulamanın diğer bölümlerine kolayca entegre edilebilir.
Geldik son adıma burda Orkestratör kullanacağiz yazılımcı arkadaşların aşina olduğu bir konu
Plugins içine text_to_video.py adında bir dosya oluşturun ve aşağıdaki kodumu yazıyoruz
import os
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import AzureTextCompletion
from myPlugins.audioPlugin.audioPlugin import AudioPlugin
from myPlugins.imagePlugin.imagePlugin import ImagePlugin
from myPlugins.videoPlugin.videoPlugin import VideoPlugin
from dotenv import load_dotenv
import time
# Semantic functions are used to call the semantic skills
# 1. Summarize the input text
# 2. Create image prompts from the summary
def semanticFunctions(kernel, skills_directory, skill_name,input):
functions = kernel.import_semantic_skill_from_directory(skills_directory, "myPlugins")
summarizeFunction = functions[skill_name]
return summarizeFunction(input)
# Native functions are used to call the native skills
# 1. Create audio from the summary
# 2. Create images from the image prompts
# 3. Create video from the images
def nativeFunctions(kernel, context, plugin_class,skill_name, function_name):
native_plugin = kernel.import_skill(plugin_class, skill_name)
function = native_plugin[function_name]
function.invoke(context=context)
def main():
#Load environment variables from .env file
load_dotenv()
# Create a new kernel
kernel = sk.Kernel()
context = kernel.create_new_context()
# Configure AI service used by the kernel
deployment, api_key, endpoint = sk.azure_openai_settings_from_dot_env()
# Add the AI service to the kernel
kernel.add_text_completion_service("dv", AzureTextCompletion(deployment, endpoint, api_key))
# Getting user input
user_input = input("Enter your content:")
# Generating summary
skills_directory = "."
print("Generating the summary............... ")
start = time.time()
result_sum = semanticFunctions(kernel, skills_directory,"summarizePlugin",user_input).result.split('\n')[0]
print("Time taken(secs): ", time.time() - start)
# Generating audio
print("Creating audio.................")
context["content"] = result_sum
context["speech_key"] = os.getenv("SPEECH_KEY")
context["speech_region"] = os.getenv("SPEECH_REGION")
start = time.time()
nativeFunctions(kernel, context, AudioPlugin(),"audio_plugin","create_audio_file")
print("Time taken(secs): ", time.time() - start)
# Generating image prompts
print("Creating Dall-e prompts.................")
start = time.time()
image_prompts = semanticFunctions(kernel,skills_directory,"promptPlugin",result_sum).result.split('\n\n')[0].split("<")[0].split('\n')
print("Time taken(secs): ", time.time() - start)
# Generating images
print("Creating images.................")
context["prompts"] = image_prompts
context["api_base"] = os.getenv("DALLE_API_BASE")
context["api_key"] = os.getenv("DALLE_API_KEY")
context["api_version"] = os.getenv("DALLE_API_VERSION")
start = time.time()
nativeFunctions(kernel, context, ImagePlugin(),"image_plugin","create_image_files")
print("Time taken(secs): ", time.time() - start)
# Generating video
print("Creating video.................")
start = time.time()
nativeFunctions(kernel, context, VideoPlugin(),"video_plugin","create_video_file")
print("Time taken(secs): ", time.time() - start)
if __name__ == "__main__":
start = time.time()
main()
print("Time taken Overall(mins): ", (time.time() - start)/60)Kodun açıklaması:
Yukarıdaki kod, çeşitli eklentiler kullanarak kullanıcının giriş metninden bir video oluşturan bir Python betiğidir. Komut dosyası, giriş metnini özetlemek, ses oluşturmak, görüntü istemleri oluşturmak ve görüntülerden video oluşturmak gibi çeşitli görevleri gerçekleştiren anlamsal ve yerel becerileri çağırmak için Anlamsal Çekirdeği kullanır.
Komut dosyası, Semantic Kernel için işlevsellik sağlayan semantic_kernel modülü ve ses, görüntü ve video oluşturmak için kullanılan çeşitli özel eklentiler de dahil olmak üzere çeşitli modüllerin içe aktarılmasıyla başlar. Dotenv modülü ayrıca ortam değişkenlerini bir .env dosyasından yüklemek için içe aktarılır.
Daha sonra Anlamsal Çekirdeğin yeni bir örneği oluşturulur ve çekirdek içinde yeni bir bağlam oluşturulur. Betik daha sonra, .env dosyasından gerekli ayarları okuyan azure_openai_settings_from_dot_env işlevini kullanarak çekirdek tarafından kullanılacak bir AI hizmetini yapılandırır.
Daha sonra kullanıcıdan giriş metnini girmesi istenir; bu metin, SummaryPlugin adı verilen semantik beceriyi kullanarak metnin bir özetini oluşturmak için kullanılır. Bu beceriyi çağırmak ve özeti döndürmek için semanticFunctions işlevi kullanılır.
Komut dosyası daha sonra audio_plugin adı verilen yerel bir beceriyi kullanarak özetten ses üretir. nativeFunctions işlevi, bu beceriyi çağırmak ve özet metni, API anahtarı ve konuşma hizmeti bölgesi dahil olmak üzere gerekli bağlam bilgilerini iletmek için kullanılır.
Daha sonra komut dosyası, PromptPlugin adı verilen başka bir anlamsal beceriyi kullanarak özetten görüntü istemleri oluşturur. Bu beceriyi çağırmak ve görüntü istemlerini döndürmek için semanticFunctions işlevi kullanılır.
Komut dosyası daha sonra image_plugin adı verilen yerel bir beceriyi kullanarak görüntü istemlerinden görüntüler oluşturur. nativeFunctions işlevi, bu beceriyi çağırmak ve DALL-E API’sinin görüntü istemleri ve API tabanı, anahtarı ve sürümü dahil olmak üzere gerekli bağlam bilgilerini iletmek için kullanılır.
Son olarak komut dosyası, video_plugin adı verilen başka bir yerel beceriyi kullanarak görüntülerden bir video oluşturur. nativeFunctions işlevi, bu beceriyi çağırmak ve görüntülerin ve sesin dosya adları ve videonun çıktı dosya adı da dahil olmak üzere gerekli bağlam bilgilerini iletmek için kullanılır.
Komut dosyası ayrıca, her adımı tamamlamak için geçen süre de dahil olmak üzere, komut dosyasının ilerleyişi hakkında bilgi sağlayan çeşitli yazdırma ifadeleri içerir. Komut dosyasını tamamlamak için geçen toplam süre de sonunda yazdırılır.
Genel olarak bu komut dosyası, metinden video oluşturmak gibi karmaşık görevleri gerçekleştirmek üzere anlamsal ve yerel becerileri çağırmak için Anlamsal Çekirdeğin nasıl kullanılabileceğini gösterir. Komut dosyası, her görev için özel olarak tasarlanmış eklentileri kullanarak, giriş metninden yüksek kaliteli ses, görüntü ve video üretebiliriz.
Eklentilerimizi başarılı bir şekilde oluşturduktan sonra bir sonraki adım, bu eklentileri kendi uygulamamız içinde kullanmak veya dışarıdan çağırmak olacaktır. İşte bu adımları daha ayrıntılı bir şekilde açıklayarak anlatalım:
- Uygulama Oluşturma: Eklentilerimiz hazır olduğuna göre, kendi uygulamamızı geliştirmeye başlayabiliriz. Bu uygulama, basit bir HTML sayfası olabileceği gibi, daha karmaşık bir yapısı olan bir Discord veya Telegram botu da olabilir.
- API Entegrasyonları: Uygulamamızı geliştirirken, Discord, Telegram gibi platformların API’lerini kullanarak bu platformlarla etkileşimde bulunabiliriz. Örneğin, Telegram’da “/komut” gibi özel komutlar veya Discord’da “/komut” ile çağrılan işlevler oluşturabiliriz. Bu şekilde ses içeriği veya görüntü içeriği gibi özel işlemler gerçekleştirebiliriz. Bu aşamada sadece hayal gücümüz sınırlıdır.
- Local İşlemler: Uygulamamızın bazı işlemlerini yerel PC üzerinde çalışan Python scriptleri gibi otomatize edilmiş işlemlerle gerçekleştirebiliriz. Bu, kullanıcıların yerel kaynakları kullanarak çeşitli görevleri gerçekleştirebilmelerine olanak tanır.
- Config Dosyaları: İşlemleri gerçekleştirirken, eklentilerimizin ve uygulamamızın yapılandırma (config) dosyalarındaki sınırları dikkate almalıyız. Bu dosyalar, uygulamanın nasıl davranacağını ve hangi sınırlar içinde çalışacağını belirler. Metin girişlerini bu yapılandırmalara uygun olarak işlemeliyiz.
Sonuç olarak, eklentilerimizi oluşturduktan sonra, kendi uygulamamızı yazmak veya platformlar arasında entegrasyonlar oluşturmak için birçok seçeneğimiz vardır. Bu süreçte yaratıcılığımız ve yapılandırmalarımızın sınırlarını dikkate alarak uygulamamızı geliştirebiliriz.
ben discorda entegre ettim çok eğlenceli oldu
eklenti kodu aşağidaki gibidir.
import requests
def handler(pd: "pipedream"):
token = f'{pd.inputs["discord"]["$auth"]["oauth_access_token"]}'
authorization = f'Bearer {token}'
headers = {"Authorization": authorization, "accept": 'application/json'}
r = requests.get('https://discord.com/api/users/@me', headers=headers)
# Export the data for use in future steps
return r.json()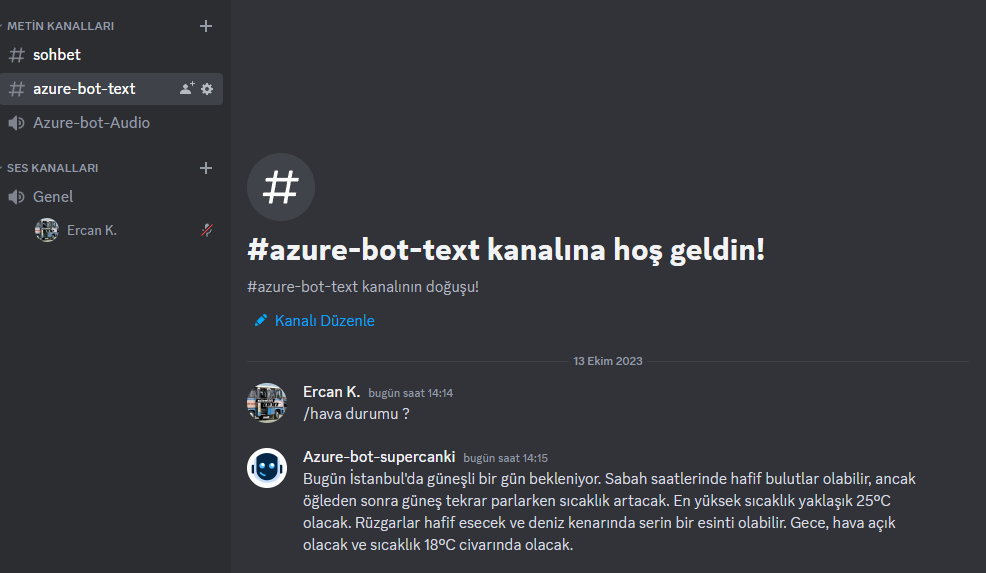
Geç cevap verme sorununun temel nedeni olarak, kullanmış olduğum Azure planının sınırlamaları yüzünden kaynaklarım çok güçsüz. Sesli metinleri tanımak ve cevaplamak için Discord API ile yaşadığım sorunlar da cabası. Bu tür sorunlarla başa çıkmadım ve kendi özel GPT’yi oluşturmak heyecan verici, ancak zaman ve enerji gerektiren bir süreç.
Bu yazıyı hazırlarken, özellikle Azure AI hizmetleri hakkında bilgi edinmek büyük önem taşıdı. Birçok kaynak ve öğrenme kaynağı bu süreci daha kolay hale getirdi. Özellikle Azure’ın “Learn” sayfası, öğrenme kaynakları ve eğitim materyalleri konusunda oldukça zengin ve başarılı bir kaynaktır, bu yüzden bu kaynağı incelemenizi öneririm.
Kısacası, Azure AI hizmetleriyle çalışırken yaşadığım sınırlamalar ve Discord API sorunları gibi zorluklar, kendi özel GPT’yi oluşturmak gibi büyük bir projeye girişmeden önce kendi beceri seviyemizi ve kaynaklarımızı değerlendirmemiz gerektiğini gösteriyor. Bu süreç, öğrenmeye ve gelişmeye açık olduğumuzda oldukça tatmin edici olabilir.
Azure Open AI: Get started with Azure OpenAI Service – Training | Microsoft Learn
Speech To Text: Speech to text overview – Speech service – Azure Cognitive Services | Microsoft Learn
Pyton :Learn Python – Free Interactive Python Tutorial
Semantic Kernel :Orchestrate your AI with Semantic Kernel | Microsoft Learn
Learndan yararlandığım kaynaklar.








Harika bir makale olmuş, eline sağlık.