Azure Databricks kümeleri, performans ve depolama maliyetleri göz önüne alındığında varsayılan olarak ağ günlüklerini kaydetmez. Eğer kümeye ilişkin çeşitli ağ sorunlarını araştırmak amacıyla tcpdump kullanarak bir TCP dökümü yakalamanız gerekiyorsa aşağıdaki adımları takip edebilirsiniz. Bu adımlar, kümenin tüm ömrü boyunca hem sürücü hem de çalışan düğümlerde bir TCP dökümü yakalayacaktır.
ve bunu herhangi bir depolama maliyeti olmadan yapacağiz bunun Azure Databricks notebook u kullanarak kendi localimde çaliştracağim ama kayit databricksde tutulacak işimiz bitince silmemiz gerekiyor ama yoksa cost ücretine maruz kalırız
Dikkat : Performanstan ve ek maliyetten kaçınmak için tcpdump’ı oluşturduktan sonra tcpdump başlatma komut dosyasını AKS ve databricks clusterinden kaldirin
Hadi başlaylım tcp dump almak isterdiğimiz clusterlarda çaliştracağimiz geniş kapsamli bir betik/script yazmak gerkiyor
Öncelikle cluster-scoped int script çaliştirmamiz gerekiyor databricks içinde catalog sekmesinde bulabilirsiniz. yok ise bir klasör açip biz oluşturalim scripti aşağida paylaşiyorum
%scala
dbutils.fs.put("dbfs:/databricks/init-scripts/tcpdump_pypi_repo.sh", """
#!/bin/bash
sudo apt update && sudo apt install --yes tcpdump
sleep 5s
set -x
if [[ $DB_IS_DRIVER = "TRUE" ]]; then
MYIP=$(hostname -I | sed 's/ *$//g')
echo "initiating tcp dump"
TCPDUMP_FILE="/tmp/trace_$(date +"%Y%m%d_%H%M")_${MYIP}.pcap"
sudo tcpdump -w $TCPDUMP_FILE -W 1000 -G 1800 -K -n -s256 host files.pythonhosted.org and port 443 &
sleep 15s
echo "initiated tcp dump `ls -ltrh $TCPDUMP_FILE`"
cat <<'EOF' >> /tmp/copy_stats.sh
#!/bin/bash
SOURCE_FILE=$1
DB_CLUSTER_ID=$(echo $HOSTNAME | awk -F '-' '{print$1"-"$2"-"$3}')
if [[ ! -d /dbfs/databricks/tcpdump/${DB_CLUSTER_ID} ]] ; then
sudo mkdir -p /dbfs/databricks/tcpdump/${DB_CLUSTER_ID}
fi
BASEDIR="/dbfs/databricks/tcpdump/${DB_CLUSTER_ID}"
#BASEDIR="/local_disk0/tcpdump/${DB_CLUSTER_ID}"
mkdir -p ${BASEDIR}
FILESIZE=0
while [ 1 ]; do
CUR_FILESIZE=$(stat -c%s "$SOURCE_FILE")
if [ "$CUR_FILESIZE" -gt "$FILESIZE" ]; then
sudo cp -f $SOURCE_FILE ${BASEDIR}/.
fi
FILESIZE=$CUR_FILESIZE
sleep 1m
done
EOF
chmod a+x /tmp/copy_stats.sh
/tmp/copy_stats.sh $TCPDUMP_FILE &>/tmp/copy_stats.log & disown
fi
""",true)Bu script bize lazim olan databricks eklerini hazirlayacak ilgili klasör ve betik dosyalarini databricks içinde kopyalacak işlem tamamlandıktan sonra clusterimizi restart etmeliyiz ki tcp dump yapabilmek için ilgili dinleme/yakalama işlemleri için hazır duruma gelsin sonrasinda istediğimiz clusterde ilgili py scriptlerini çaliştirarak TCP dökümü /dbfs/databricks/tcpdump/${DB_CLUSTER_ID} yolunda oluşturulacak
Bakın aşağidaki resimde ilgili yerlere dosyaları oluşturduğunu göreceksiniz

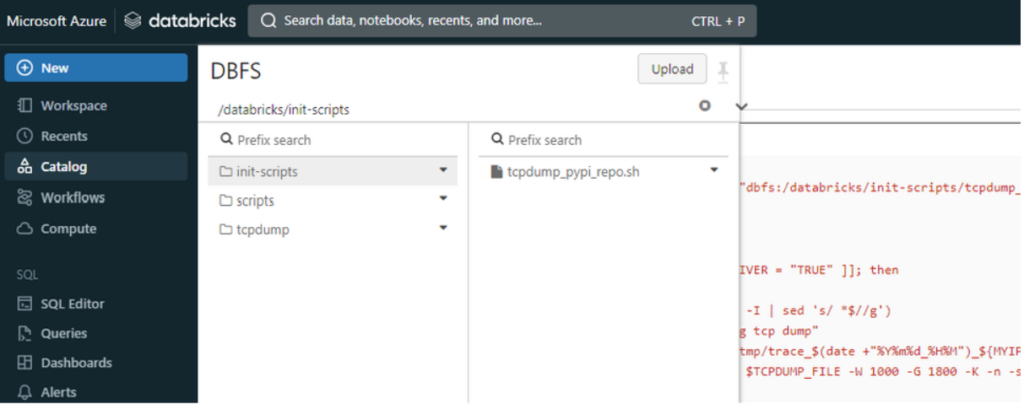


AKS databricks clusterimizda da bi kaç ayar etkinleştirmemiz gerekiyor bende sonradan öğrendim dump yazamayip hatalar ile karşilaşmiştim onlarıda ekliyorum aşağidaki ayalari açik tutmalisiniz işiniz bitince kapatmalisiniz (cost mailyet dikkat edin.)
Clusterin compute menüsündeki ayarlar init scripts yolu görünüyormu kontrol edelim.

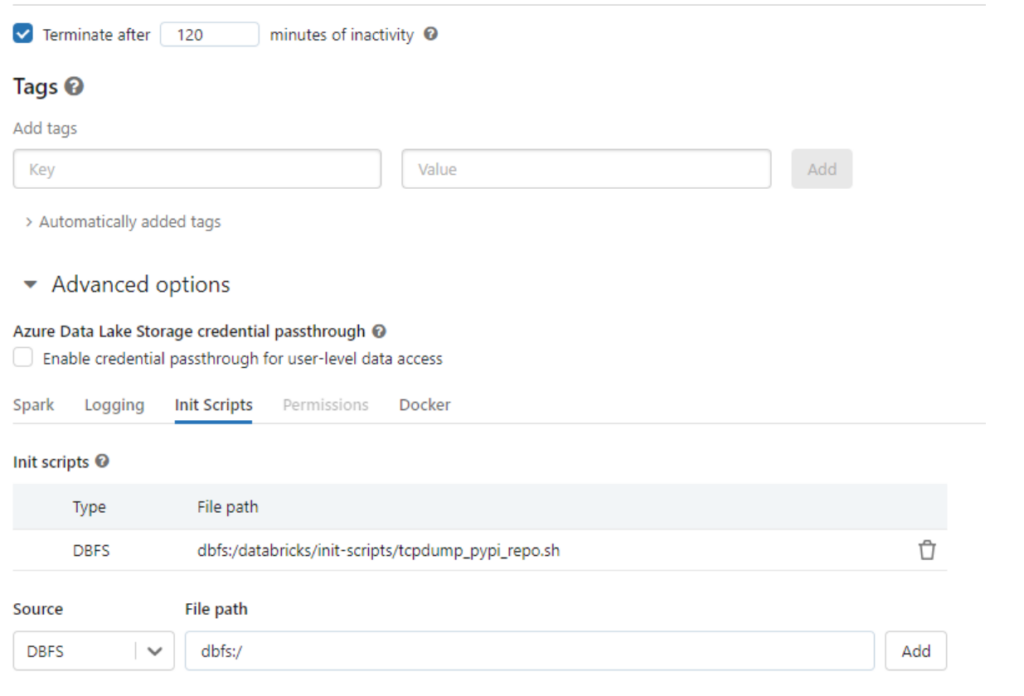
Logging sekmesinde loggin ayarinida seçelim

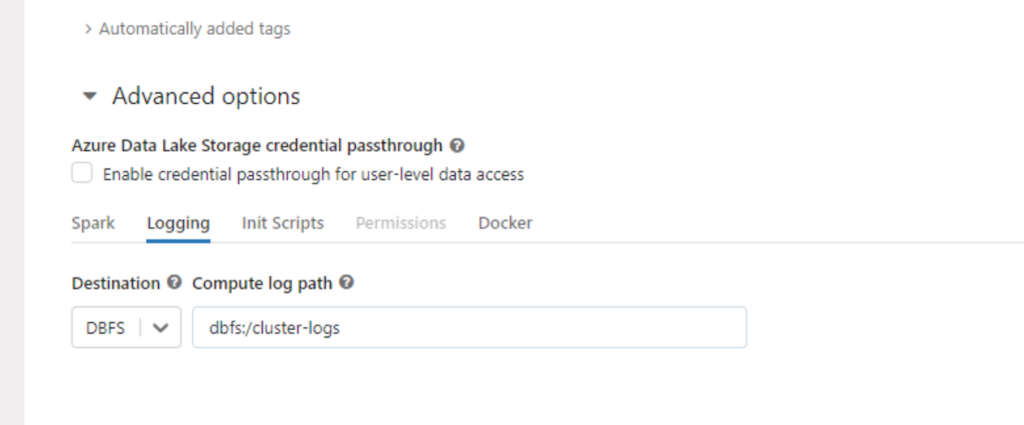
bakın örnek dumplarda burada birikiyor

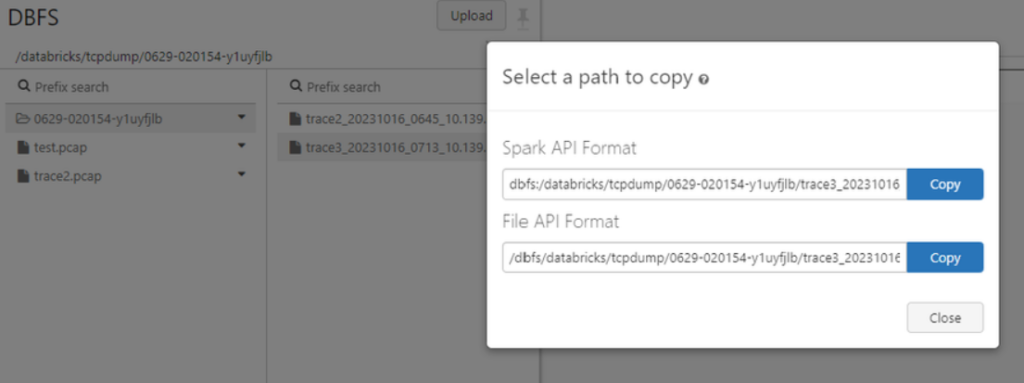
peki ayarları yaptık scripti hazirladik nasil yapacağiz nasil çaliştiracağiz bu scripti diyorsunuz hemen bu adıma geçelim görelim bakalim nasil yapacağiz powershell ile alabilir databricks gui arayüzü zaten yukarda gösterdim ben powershell tercih ediyorum
1 Databricks CLI local PC mize yüklememiz gerekiyor
Powershell 7 kullanmanizi tavsiye ederim aşağidaki komut ile yükleyelim
pip install databricks-cliYükleme işlemi tamamlandiktan sonra databricks e token ile bağlanmamiz gerekiyor komutu aşağidaki gibi
databricks configre --tokennasil token alip hosta nasil bağlaniyoruz teknik dökümanina bakarak öğrenebilirsiniz linki birakiyorum
bağlanti işinide halletikten sonra CLI mizde
databricks fs ls komutu ile dumplarimizi listeliyoruz intil scripti clusterden seçtiğimiz için GUI tarafda otomatik olarak sürekli çalişiyor olacak bişey çaliştirmamiza gerek yok extradan
bu şekilde SQL servisleri tcp servisleri AKS servisleri network dumplari gibi değişik servisleri dumplayabiliriz ama intil scriptide buna göre editlemek ve servisler için token almamiz gerekir yararlandiğim teknik dökümanlarin linklerinide aşağiya birakiyorum
https://learn.microsoft.com/en-us/azure/databricks/init-scripts/cluster-scoped
https://learn.microsoft.com/en-us/azure/databricks/dev-tools/cli/
Bu makalede temel azure AKS ve CLI bilginiz olduğunu varsaydim databricksi zaten çözersiniz kullanimi çok basit özet olarak intil scripti ile aslinda databricks jobu oluşturduk o çalişip bizim için dump topladi diyebiliriz.