
Bir önceki makalemizin devamı olan bu makalemizde de öneri modellerinden İşbirlikçi yaklaşım modelini inceleyecek ve detaylandıracağız.
İşbirlikçi yaklaşımın herhangi bir ürünü kullanıcımızın nasıl değerlendirebileceğini tahminlemek’tir. Yani burada çalışma şeklimiz ve asıl elde etmek istediğimiz derecelendirme matrisidir. Bu derecelendirme matrisi sitemiz üzerinde kayıtlı olan her bir kullanıcımızın derecelendirdiği ve puanladığı ürünleri içermektedir. Aşağıdaki temsili resimde de görüleceği üzere her iki kişinin alışkanlıkları aynıdır. Ve bunlardan bir tanesinin almış olduğu bir ürün diğer kullanıcımıza öneri olarak sunulacaktır. Öneri olarak sunulacak olan ürün ise tamamıyla işbirlikçi yaklaşım modelinin örneğidir. Yani öneride bulunulacak kişi, sitemiz üzerinde bulunan ve kendisine benzer olan bir kullanıcının yaptığı harekete göre ortaya çıkan bir öneri motorudur.




Pekala böyle bir öneri sisteminin matematiğini açıklayacak olur isek ;
Matematiksel olarak öneri motorlarında matrislerden faydalanırız. Derecelendirme matrisi olarak isimlendirilen bu matrisimizin detaylarından bahsedecek olursak;
Derecelendirme matrisinde satırlarımız kullanıcıları ifade etmektedir. Yani sitemizde kayıtlı olan kullanıcı sayımız kadar matrisimizin de satırı olacaktır. Matrisimizin sütunları da sitemizde mevcut olan ürünleri içermektedir. Yani buda ürün sayımız kadar matrisimizin de sütunları olacağı anlamına gelir.
Sitemizde kayıtlı olan kullanıcılarımız tarafından her bir ürün için bir derecelendirme değeri olduğuna dikkat etmeliyiz. Çünkü matrisimizin içerisindeki her bir öğe temel olarak belirli bir kullanıcının yine belirli bir ürünü ne kadar seveceğini ve ne kadar puanlayacağının tahminlemesi’ni yapacaktır.
Yani özetle matrisimizde bulunan her bir satır kullanıcılarımızı, her bir sütun ise kataloğumuzda ki ürünlerimizin kullanıcılarımız tarafından derecelendirilmesi ve ya puanlandırılmasını ifade edecektir.


Yukarıda ki göreceğiniz resimde de satırlarımız kullanıcıları ifade ederken, her bir kolonumuzda kullanıcılarımız tarafından değerlendirilmiş ürünleri ifade etmektedir. Bu matrisimizde bir eleman düşünelim ürün için P kullanıcımız için U olarak ifade edelim. U kullanıcısı P ürününe 5 puan olarak derecelendirildiğini görebiliriz.
P ürününün derecelendirilmesi çok nadir olabilir. Belki kullanıcımızın derecelendirdiği bir film ise bu filmi daha önce izlemiş ya da ürün ise derecelendirdiği daha önce kullanmış olabilme ihtimalide bulunmaktadır. Varmak istediğimiz nokta şu kataloğumuzda milyonlarca ürün olabilir ve her bir kullanıcı bunlardan sadece bir kaçını derecelendirebilir, alabilir ya da puanlayabilir. İşte bu noktada bahsettiğimiz şey ve varsaydığımız ise bu değerlerimiz eksik olması üzerine kuruludur. Asıl olan ve en önemli olan amacımız da işte bu noktada ortaya çıkmaktadır yani eksik olan bilgiyi tahminlemektir. Bu değeri tanımlayacak olan gizli faktörü tanımlayabiliyor ya da tahminleyebiliyor isek derecelendirme matrisimizde değerimizi ekleyebiliriz anlamına gelmektedir.
Kullanıcı bir ürünü değerlendirmedi ve kullanıcımızın bu ürün için puanın ne olabileceğini düşünüyoruz?
Burada değerlendirilmemiş bir ürünle ilgili tahminleme yaparken neleri dikkate alacağız. Burada bu sorulara cevaplar verebilmek için gizli faktörleri bulmamız ve gerçekten veri setimizi iyi anlamamız gerekmekte. Bizler gizli faktörleri anlamak istiyoruz. Örneğin bir film öneri sisteminde filmlere verdiğimiz dereceleri temel alarak komedi sevdiğimizi fakat dram ya da gerilim filmlerinden hoşlanmadığınızı belirleyebiliriz. Yani kategori olarak bir faktör ortaya koyabiliriz.
Derecelendirmelerizi hangi gizli faktörlerin artırdığını belirlemek ise öneri motorlarında en yaygın olarak kullanılan bir tekniktir ve buna gizli faktör analizi adı verilmektedir.
Tahmini derecelendirme matrisinin değerinin ne olacağını anlamak için bir dizi gizli faktör seçimleri yapmamız gereklidir. Örneğin üç adet gizli faktör seçimi yaptık. Bu faktörler gizlidir ve ne olduğunu da henüz bilmiyoruz. Bunlar kullanıcılarımızın ürün derecelendirilmesinde kullanılacak parametreler olup bu değerlere göre kullanıcımızın ürün için vereceği puanlamayı tahminlemekte kullanılacaklardır.
Bu gizli faktörler göz önüne alındığında kullanıcı ürün matrisi olarak da adlandırılan orijinal derecelendirme matrisi ile gizli faktörler matrisinin çarpımı ile elde edilir.

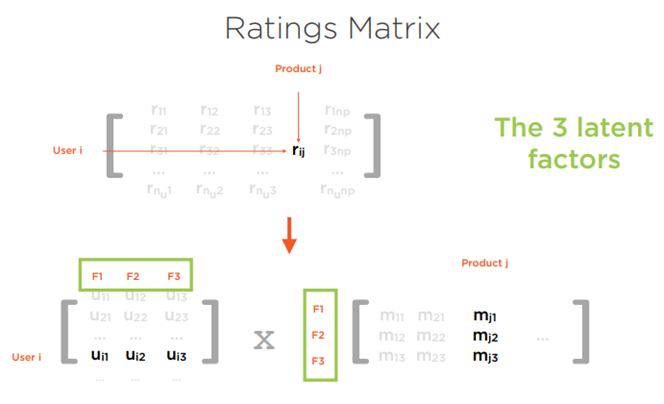
Bu matrislerden birincisi kullanıcıları ve ürünleri içeren matrisimizdir. Bir diğeri ise tanımladığımız ve üç adet olarak belirlediğimiz gizli faktörlerden oluşan matrisimizdir. Bu elimizdeki orijinal kullanıcı matrisimiz ile gizli faktör matrisimizi çarparak bizim derecelendirme matrisimizi elde edeceğimizi söylemiştik.



Kullanıcı matrisimizin gizli faktörlerininde her biri için bir değeri ya da puanı vardır.
Şimdi bu noktaya kadar olan kısımlarda öneri sistemleri türleri, nasıl bir matematiğe sahip oldukları gibi konulardan bahsettik. Şimdi ise işin matematiksel kısımlardan uzaklaşarak Spark üzerinde bu işlemleri nasıl ve ne şekilde uygulanacağından bahsedelim.
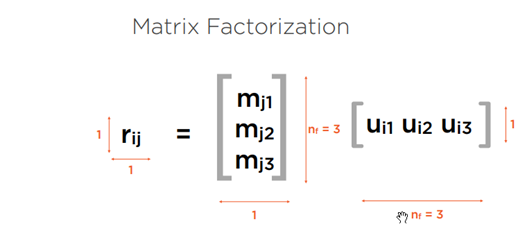
Formülde de gördüğümüz üzere bulmaya ve erişmeye çalıştığımız R değerini bilmiş olsaydık derecelendirme formülü üzerinde bulunan U ve M parametrelerini bulmak için farklı ve birden fazla yolumuz olabilirdi. Fakat bizlerin ihtiyacı olan R değerinin bulunması bu yüzden diğer detaylarla çok fazla uğraşmayacağız.
Spark üzerinde bu işlemler için Alternating Least Square (ALS) algoritmamızı kullanarak bu işlemlerimizin hepsini gerçekleştirebilecek ve istediğimiz R değerine ulaşabilir olacağız. ALS aslında sayısal bir algoritma olup Spark üzerinde kütüphane olarak kullanılabilecek durumdadır. Böylelikle bizlerin daha önceki paragraflarda matematiksel olarak ifade ettiğimiz gizli faktör matrislerinin, orijinal matrisler ile çarpılması gibi matematiksel detaylardan bizleri uzaklaştırmaktadır. Özetleyecek olur isek derecelendirme matrislerimizi tahminlemek için Spark üzerinde ALS kütüphanesinden yararlanacağız.
Kullanıcı ve ürün matrisimizin her bir elamanı aslında bizim formülüze ettiğimiz U ve M değişkenlerinin değer büyüklükleri artık düşünmek zorunda değiliz. Yani biliyoruz ki derecelendirme matrisinde yer alan elemanlar sahip olduğumuz kullanıcılar ve ürünlerden oluşmaktaydı. Ayrıca kullanıcılarımızın derecelendirmeleri ya da yine ileri ki uygulamalarımızda göreceğimiz örtülü derecelendirme değerleri büyük olabilir. Büyük olan değerlerin hesaplanması gibi koşullar ve zorluklarla da artık ALS Kütüphanesi yardımı ile düşünmediğimiz bir durum olarak karşımızda bulunmaktadır.
Bu konuyla ilgili önemli bir detay vermek gerekir ise yine bir sonraki örtülü derecelendirme diye ifade edeceğimiz örneklerimizde matrisimiz içerisinde yer alan ve tahminlemek için kullanacağımız büyük değerlerinde bir standardizasyonunu sağlamamız gerekmektedir. Her ne kadar bir önceki paragrafta büyüklük gibi işlemler ALS ile artık gözümüzü korkutmuyor diyor olsak da, algoritmamızın çıktılarında yüksek oranlarda doğruluk elde edebilmek için bir regülasyona ihtiyaç duyarız.
Öneri sistemleri türleri, matematiksel olarak ifadeleri ve bizlerin Spark üzerinde bu işlemlerin ne şekilde kullanılacağını anlatmaya çalıştım. Bundan sonra ki makale serimde ise öneri sistemleri uygulamaları geliştirilmesi ve uygulanması konularından bahsedeceğiz.