
Anthropic, Mantık Yürütebilen Hibrit AI Modeli Claude 3.7 Sonnet’i Duyurdu
Anthropic, yapay zeka dünyasında bir ilke imza atarak “düşünebilen” yeni bir AI modeli olan Claude 3.7 Sonnet’i kullanıma sundu. Bu model, kullanıcıların sorularına hem anlık hem de daha derinlemesine düşünülmüş yanıtlar verebiliyor. Kullanıcılar, modelin “düşünme” süresini kendileri belirleyebiliyor.
Anthropic’in Hibrit AI Akıl Yürütme Modeli Neler Sunacak?
Claude 3.7 Sonnet, endüstrinin ilk “hibrit AI akıl yürütme modeli” olarak tanıtıldı. Bu model, tek bir yapı içinde hem anlık yanıtlar hem de daha kapsamlı düşünülmüş cevaplar sunabiliyor. Kullanıcılar, modelin düşünme yeteneklerini aktif hale getirerek, sorulara daha detaylı yanıtlar alabiliyor.

Anthropic, bu adımla kullanıcı deneyimini basitleştirmeyi hedefliyor. Günümüzde birçok AI asistanı, farklı maliyet ve yeteneklere sahip birden fazla model arasında seçim yapmayı gerektiriyor. Ancak Anthropic, tek bir modelin tüm ihtiyaçları karşılamasını amaçlıyor.
Claude 3.7 Sonnet, tüm kullanıcılar ve geliştiriciler için pazartesi günü erişime açıldı. Ancak modelin düşünme özelliklerine sadece Anthropic’in premium planlarını kullananlar erişebilecek. Ücretsiz kullanıcılar ise standart versiyonu kullanacak. Anthropic, bu standart versiyonun bile önceki model olan Claude 3.5 Sonnet’ten daha iyi performans gösterdiğini iddia ediyor.
Claude 3.7 Sonnet, 1 milyon giriş tokeni için 3 dolar ve 1 milyon çıkış tokeni için 15 dolar ücretlendiriliyor. Bu fiyat, OpenAI’ın o3-mini ve DeepSeek’in R1 modellerine kıyasla daha yüksek. Ancak bu modeller, Claude 3.7 Sonnet gibi hibrit bir yapıya sahip değil. Claude 3.7 Sonnet, soruları yanıtlarken içsel bir planlama süreci kullanıyor. Bu süreç, kullanıcılara “görünür bir taslak” olarak sunuluyor. Ancak güvenlik nedenleriyle bazı kısımlar kısıtlanabiliyor. Model, özellikle zorlu kodlama problemleri ve otomatik görevler gibi gerçek dünya uygulamaları için optimize edildi.
Claude 3.7 Sonnet Rakiplerine Büyük Bir Fark Atmayı Başardı
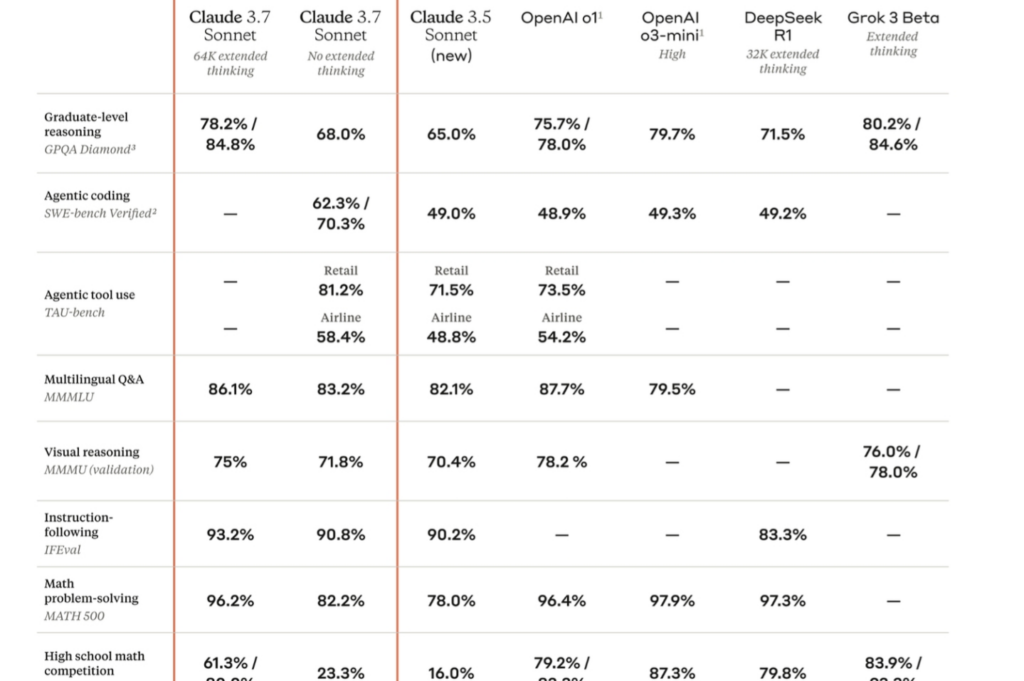
Claude 3.7 Sonnet, SWE-Bench adlı bir kodlama testinde %62,3 doğruluk oranıyla OpenAI’ın o3-mini modelini (%49,3) geride bıraktı. Ayrıca, TAU-Bench testinde %81,2’lik bir skor elde ederek OpenAI’ın o1 modelini (%73,5) geçti.
Anthropic, modelin zararlı ve zararsız sorgular arasında daha iyi ayrım yapabildiğini ve gereksiz reddetmeleri %45 oranında azalttığını belirtiyor. Bu, diğer AI laboratuvarlarının kısıtlama politikalarını yeniden gözden geçirdiği bir dönemde önemli bir gelişme.
Anthropic, Claude 3.7 Sonnet ile birlikte Claude Code adlı bir kodlama aracını da tanıttı. Bu araç, geliştiricilerin terminal üzerinden doğrudan Claude’u kullanarak kod projelerini analiz etmesine ve düzenlemesine olanak tanıyor.








