
Amazon S3 AWS’nin nesne tabanlı depolama servisidir. Amazon S3 verileri bucket (kova) içinde nesne olarak depolar.Bir nesne bir dosyadan veya bu dosyayı tanımlayan bir meta veriden oluşabilir.S3 servisi block tabanlı bir depolama servisi olmadığı için S3 üzerinden işletim sistemi kurulumları yapılamaz. Sadece klasör ve dosya olarak objeler depolanabilir. Dropbox veya GoogleDrive gibi düşünebiliriz.
Amazon S3 Nesne Özellikler:
- Sıfır KB’dan 5TB’a kadar büyüklükteki dosyaları depolayabiliriz.
- S3 limitsiztir ancak tek bir dosyanın max büyüklüğü 5TB olabilir.
- S3 depolama birimlerine Bucket (Kova) denir.
- S3 nesneleri obje veya metadata olabilir.
- Metada obje ile birlikte tutulan veri hakkındaki verilerdir. Örneğin dosyanın boyutu, oluşturuma tarihi gibi veriler o objeyle bilirkte tutulan metadatalardır.
- S3 içinde oluşturulan Bucketların isimleri benzersiz olmalıdır. Bucketa verdiğiniz isim daha önce AWS üzerinde kullanılmış bir isimse AWS sizi uyararak yeni bir isim belirlemenizi ister.
- S3 global bir servis değildir. Region bazlıdır. O yüzden hangi Regionda oluşturursanız oraa konumlandırılır. Ve tüm regionlara dağıtılmaz
Amazon S3 Storage Classes (Sınıfları):
- Amazon S3 Standart; S3 Standard, sık erişilen veriler için yüksek dayanıklılık, kullanılabilirlik ve performans nesnesi depolaması sunar. Düşük gecikme süresi ve yüksek verimlilik sağladığı için S3 Standard, bulut uygulamaları, dinamik web siteleri, içerik dağıtımı, mobil ve oyun uygulamaları ve büyük veri analitiği gibi çok çeşitli kullanım durumları için uygundur.
- Düşük gecikme süresi ve yüksek performans için tasarlanmıştır.
- 3’ten fazla Availability Zones’a nesneleri kopyalarayarak % 99.999999999′ düzeyinde dayanıklılık sağlar..
- Belirli bir yılda % 99,99 erişilebilirlik için tasarlanmıştır
- Aktarılan veriler ve beklemedeki verilerin şifrelenmesi için SSL’yi destekler
- Nesnelerin diğer S3 Depolama Sınıflarına otomatik olarak taşınması için S3 Lifecycle yönetimini destekler
- Amazon S3 Standard-Infrequent Access (S3 Standard-IA); S3 Standart IA, daha az erişilen ancak gerektiğinde hızlı erişim gerektiren veriler içindir. S3 Standard-IA, GB başına düşük depolama fiyatı ve GB başına alma ücreti ile yüksek dayanıklılık, yüksek verim ve düşük gecikme süresi sunar. Bu nedenle sürekli erişilen dosyaların burada depolanmaması gerekiyor çünkü erşim ve dosya almak için ücret ödenmektedir. Düşük maliyet ve yüksek performansın bu birleşimi, S3 Standard-IA’yı uzun süreli depolama, yedeklemeler ve olağanüstü durum kurtarma dosyaları için bir veri deposu olarak ideal hale getirir.
- Aynı düşük gecikme süresi ve S3 Standardının yüksek verimlilik performansı
- 3’ten fazla Availability Zones’a nesneleri kopyalarayarak % 99.999999999′ düzeyinde dayanıklılık sağlar.
- Belirli bir yılda% 99,9 erişilebilirlik için tasarlanmıştır.
- Aktarılan veriler ve beklemedeki verilerin şifrelenmesi için SSL’yi destekler
- Nesnelerin diğer S3 Depolama Sınıflarına otomatik olarak taşınması için S3 Lifecycle yönetimini destekler
- Amazon S3 One Zone-Infrequent Access (S3 One Zone-IA); S3 One Zone-IA, daha az erişilen ancak gerektiğinde hızlı erişim gerektiren veriler içindir. En az üç Availability Zones (AZ) veri depolayan diğer S3 Depolama Sınıflarının aksine, S3 One Zone-IA verileri tek bir AZ’de depolar ve maliyeti S3 Standard-IA’dan% 20 daha azdır. S3 One Zone-IA, nadiren erişilen veriler için daha düşük maliyetli bir seçenek isteyen ancak S3 Standard veya S3 Standard-IA’nın kullanılabilirliğini ve esnekliğini gerektirmeyen müşteriler için idealdir. Şirket içi verilerin veya kolayca yeniden oluşturulabilen verilerin ikincil yedek kopyalarını depolamak için iyi bir seçimdir. S3 Cross-Region Replication kullanılarak başka bir AWS Bölgesinden çoğaltılan veriler için uygun maliyetli depolama olarak da kullanabilirsiniz.
- Aynı düşük gecikme süresi ve S3 Standardının yüksek verimlilik performansı
- Tek bir Availability Zones’a nesneleri kopyalarayarak % 99.999999999′ düzeyinde dayanıklılık sağlar. Ancak S3 One Zone-IA, verileri tek bir AWS Availability Zones sakladığından, bu depolama sınıfında depolanan veriler Availability Zones imhası durumunda kaybolacaktır.
- Belirli bir yılda% 99,5 erişilebilirlik için tasarlanmıştır.
- Aktarılan veriler ve beklemedeki verilerin şifrelenmesi için SSL’yi destekler
- Nesnelerin diğer S3 Depolama Sınıflarına otomatik olarak taşınması için S3 Lifecycle yönetimini destekler
- Amazon S3 Intelligent-Tiering (S3 Intelligent-Tiering); S3 Intelligent-Tiering depolama sınıfı, performans etkisi veya operasyonel yük olmadan verileri otomatik olarak en uygun maliyetli erişim katmanına taşıyarak maliyetleri optimize etmek için tasarlanmıştır. Nesneleri iki erişim katmanında depolayarak çalışır: sık erişim için optimize edilmiş bir katman ve sık olmayan erişim için optimize edilmiş başka bir düşük maliyetli katman. Nesne başına küçük bir aylık izleme ve otomasyon ücreti için Amazon S3, S3 Intelligent-Tiering’deki nesnelerin erişim modellerini izler ve 30 gün boyunca erişilemeyenleri sık olmayan erişim katmanına taşır. Seyrek erişim katmanındaki bir nesneye erişilirse, otomatik olarak sık erişim katmanına geri taşınır. S3 Intelligent-Tiering depolama sınıfını kullanırken geri alma ücreti yoktur ve nesneler erişim katmanları arasında taşındığında ek katman ücreti yoktur. Bilinmeyen veya öngörülemeyen erişim kalıplarına sahip uzun ömürlü veriler için ideal depolama sınıfıdır. S3 Depolama Sınıfları nesne düzeyinde yapılandırılabilir ve tek bir bucket S3 Standardı, S3 Intelligent-Tiering, S3 Standard-IA ve S3 One Zone-IA’da depolanan nesneleri içerebilir. Nesneleri doğrudan S3 Akıllı Katmana yükleyebilir veya nesneleri S3 Standard ve S3 Standard-IA’dan S3 Intelligent-Tiering’a aktarmak için S3 Lifecycle ilkelerini kullanabilirsiniz. S3 Intelligent-Tiering’dan S3 Glacier’e nesneleri de arşivleyebilirsiniz.
- Aynı düşük gecikme süresi ve S3 Standardının yüksek verimlilik performansı
- Aylık küçük monitoring and auto-tiering (katmanlama) ücreti alınır.
- 3’ten fazla Availability Zones’a nesneleri kopyalarayarak % 99.999999999′ düzeyinde dayanıklılık sağlar..
- Belirli bir yılda % 99,9 erişilebilirlik için tasarlanmıştır
- Aktarılan veriler ve beklemedeki verilerin şifrelenmesi için SSL’yi destekler
- Nesnelerin diğer S3 Depolama Sınıflarına otomatik olarak taşınması için S3 Lifecycle yönetimini destekler
- Amazon S3 Glacier (S3 Glacier); S3 Glacier, veri arşivleme için güvenli, dayanıklı ve düşük maliyetli bir depolama sınıfıdır. Şirket içi çözümlerle rekabetçi veya bunlardan daha ucuz olan maliyetlerde istediğiniz miktarda veriyi güvenle depolayabilirsiniz. Maliyetleri düşük tutmak ve değişen ihtiyaçlara uygun tutmak için S3 Glacier, birkaç dakikadan saatlere kadar üç geri alma seçeneği sunar. Nesneleri doğrudan S3 Glacier’a yükleyebilir veya S3 Lifecycle ilkelerini kullanarak S3 Standard, S3 Intelligent-Tiering, S3 Standard-IA ve S3 One Zone-IA arasında veri aktarmak için kullanabilirsiniz.
- Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive); S3 Glacier Deep Archive, Amazon S3’ün en düşük maliyetli depolama sınıfıdır ve yılda bir veya iki kez erişilebilen veriler için uzun süreli saklama ve dijital korumayı destekler. Mevzuata uyumluluk gereksinimlerini karşılamak için veri setlerini 7-10 yıl veya daha fazla tutan müşteriler – özellikle Finansal Hizmetler, Sağlık Hizmetleri ve Kamu Sektörleri gibi yüksek derecede düzenlenmiş endüstrilerdeki müşteriler için tasarlanmıştır. S3 Glacier Deep Archive ayrıca yedekleme ve felaket kurtarma kullanım durumları için de kullanılabilir ve şirket içi kütüphaneler veya şirket dışı hizmetler olsun manyetik bant sistemlerine uygun maliyetli ve yönetimi kolay bir alternatiftir. S3 Glacier Deep Archive, verilerin düzenli olarak alındığı ve bazı verilerin dakikalar içinde gerekli olabileceği arşivler için ideal olan Amazon S3 Glacier’ı tamamlar. S3 Glacier Deep Archive’da depolanan tüm nesneler,% 99.999999999 dayanıklılık ile korunan, coğrafi olarak dağınık en az üç Bölgede çoğaltılır ve saklanır ve 12 saat içinde geri yüklenebilir.
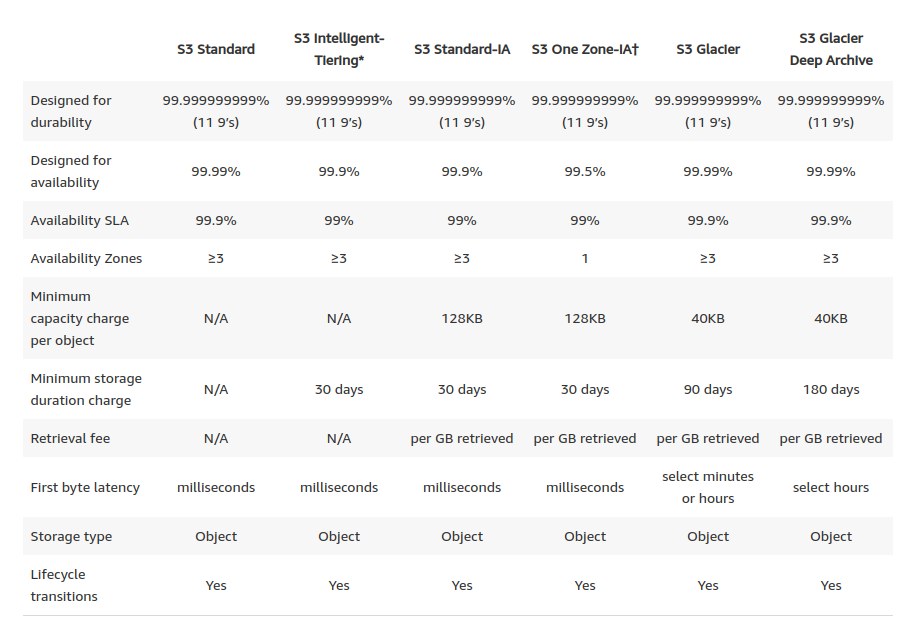

S3 Fiyatlandırılması :
S3 serviside diğer tüm AWS servisleri gibi size önceden bri maliyet çıkartmaz ve sadece kullandığınız kadar ücret ödemenizi sağlar bu yüzden bir başlangıç maliyeti yoktur. Amazon S3 servisini fiyatlandırırken 3 temel metrik üzerinden hesaplar
- Toplam depolanan verinin boyutu GB cinsinden hesaplama; Burada S3’ü hangi katmanda kullandığınıza göre GB fiyatı değişecektir. En pahalı S3 Standart katmanıyken, S3 Standart IA katmanı daha ucuzken, S3 One Zone IA ise diğer ikisinden de daha ucuz GB başı fiyata sahiptir.
- S3’ten dış dünyaya transfer edilen verinin boyutu; Örneğin sizin S3’te 2GB veriniz var ve 1 ay boyunca bu veriye 10GB download etmişseniz S3 sizden bu 10GB’da erişim ücretini alır.
- Toplam obje erişim isteği sayısı; AWS S3’te bulunan her dosyaya erişim isteğinide ücretlendirir. Bu ücret çok küçük bir miktardır.
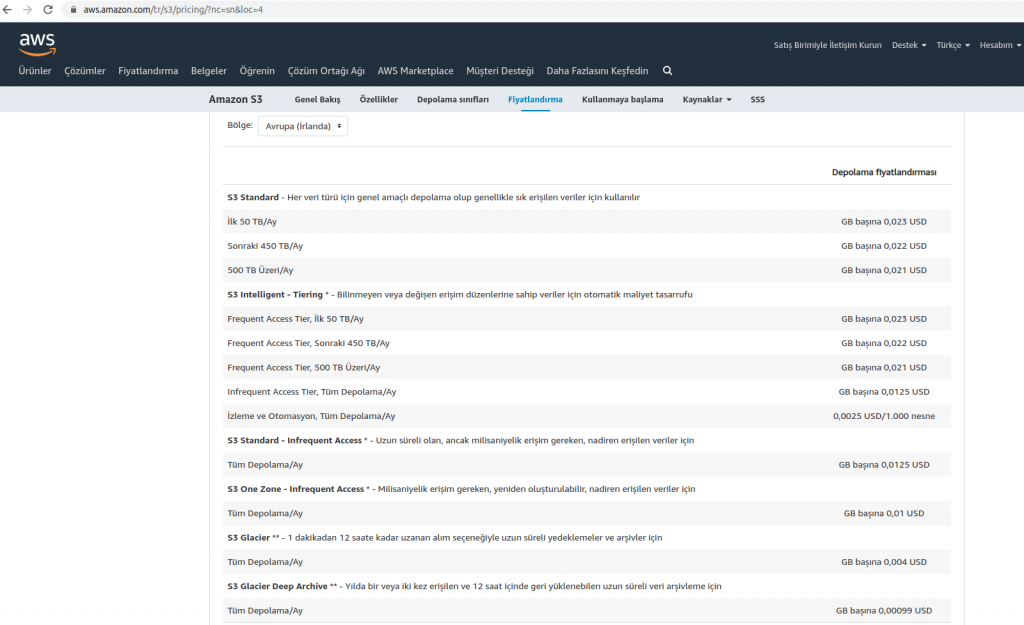
Amazon S3 servisinin güncel fiyatlama toplası aşağdaki gibidir. Regionlar arasında fark olabilir biz Avrupa’da kurulan ilk Region olan İrlanda’nın fiyat listesini görüntüledik.
AMAZON S3 UYGULAMA1
Amazon S3 detaylı olarak uygulamadan önce basit bir Bucket (Kova) oluşturalım ve içine dosya atarak bazı özelliklerine bakalım. Objeler AmazonS3’te Bucketler içinde depolanır.
Services menüsünden Storage menüsüne gelerek S3 seçebiliriz veya Find Services alanındna S3 yazarak artıp seçebiliriz. Services altında Storage gelip buradan Amazon S3 seçiyoruz.
Create bucket seçerek Bucket oluşturmaya başlıyoruz.
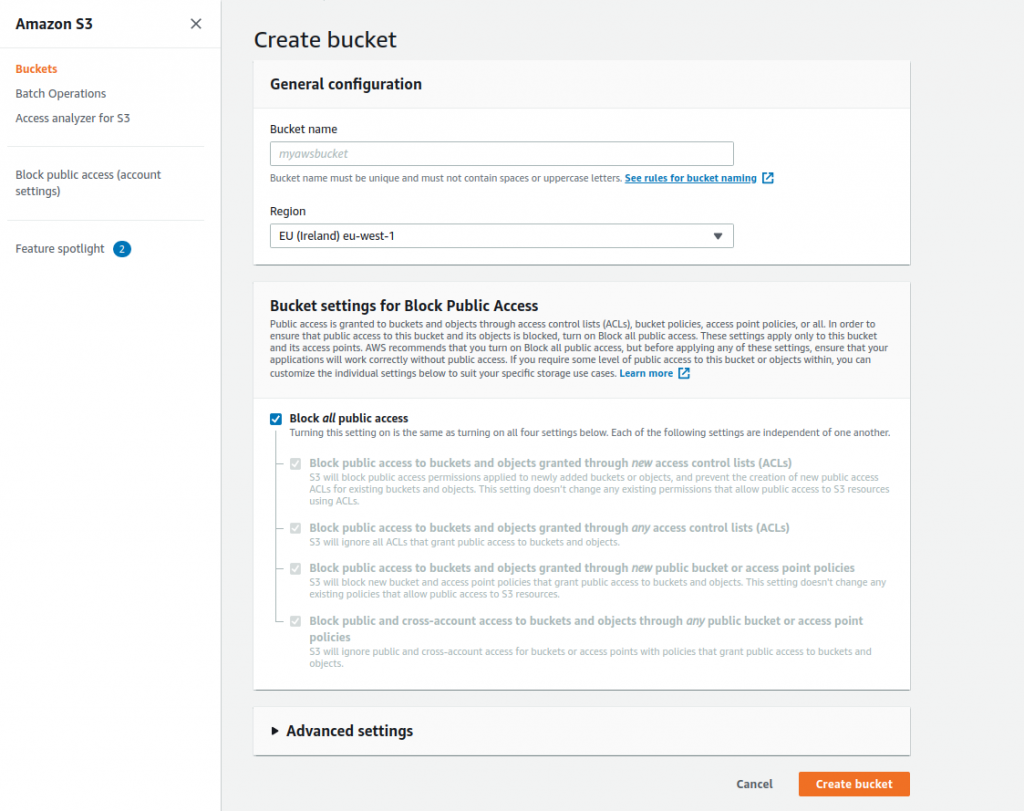
- Bucket Name; Bucket’a bir isim veriyoruz. Bucket ismi AWS içinde benzersiz olmak zorunda, veridiğiniz isim AWS üzerinde başka bir bucket için kullanılmışsa bu ismi Bucket’a veremezsiniz Bucket ismi aşağdaki özelliklerden oluşur. Biz Bucket’a “karatekin-it-23” ismini vereceğiz
- Bucket isimleri minimum 3, maksimum 63 karakter uzunluğunda olabilir.
- Bucket isimleri yalnızca küçük harfler, sayılar,nokta(.) ve kısa çizgilerden(-) oluşabilir.
- Bucket isimleri harf veya sayı ile başlayıp bitmelidir.
- Bucket isimleri IP adresi (10.10.20.253) olarak oluşturulmamalıdır.
- Bucket isimleri bulunduğu bölümde benzersiz olmalıdır. AWS’nin şuan üç bölümü bulunmaktadır. aws (Standart Bölgeler), aws-cn (Çin Bölgeleri) ve aws-us-gov (AWS GovCloud [ABD] Bölgeleri).
- Region; Bucket global bir servis değildir. Regionlarda oluşturulur ve oluşturulduğu regionda hizmet verir. Bucket ismi oluşurken bulunduğu region tanımda yer alır. Biz İrlanda’yı seçeceğiz.
- Bucket settings for Block Public Access; AmazonS3 hizmeti bir kaç sene önceye kadar oluşturulan Bucket’ları genel erişime açıyordu. Oluşturduğunuz Bucket dünyanın her yeridne erişim izni olması zaman içinde güvenlik sorununa neden olduğu için Amazon bir kaç yıl önce genel erişim izini defaulta kapalı olacak şekilde güncelledi. Biz yapacağımız testler için şimdilik bu seçeneği devre dışı bırakıyor ve Public Accessi devreye alıyoruz. Public Access devreye aldığımız AWS bize “I acknowledge that the current settings might result in this bucket and the objects within becoming public.” bir onaylama metni sunuor ve bunu kabul etmemizi istiyor. Kısaca “Geçerli ayarların bu gruba ve içindeki nesnelerin herkese açık hale gelmesine neden olabileceğini kabul ediyorum.” diyerek Create Bucket diyerek Bucketımızı oluşturuyoruz.
- Bucket’lara 3 şekilde erişim sağlanır. Birinci erişim yöntemi oluşturduğumuz IAM Userlarına verdiğimiz yetki ile gerçekleştirilir. İkinci olarak başka bir AWS’hesabından yada kimlik yönetim sistme üzerinden gelen kullanıcılar için oluşturuğumuz IAM Rolleri üzerinden erişilebilir. Üçüncü olarakta Public Access yani herkesin erişimine açılabilir.
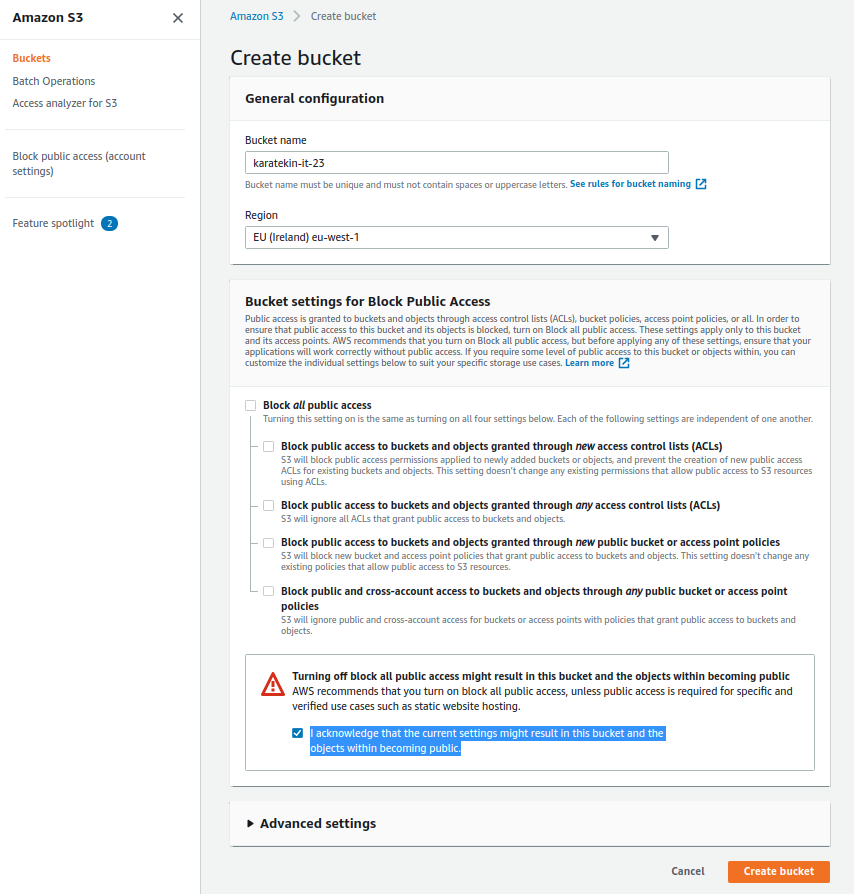

Şimdi oluşturduğumuz Bucket’ı seçerek içindeki Upload seçeneğini kullanarak S3 Bucket’ımıza bir kaç dosya depolayalım
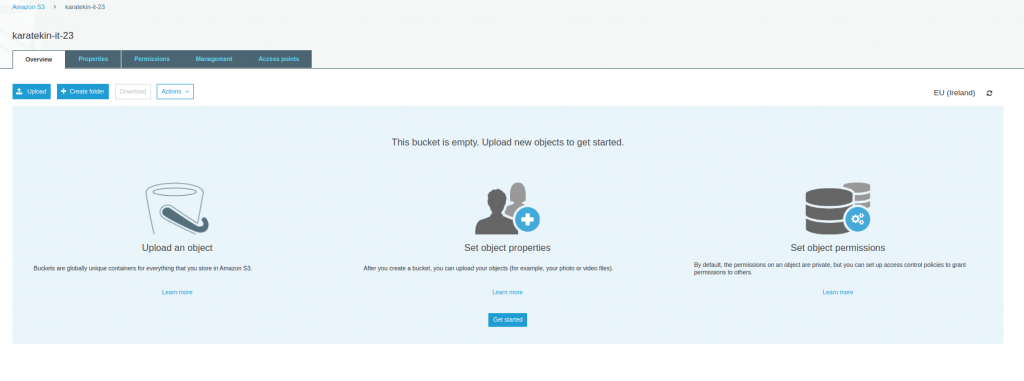
Upload’ı seçtiğimizde kaşrımıza çıkan ekranda bir uyarı ile karşılaşacağız. “ To upload a file larger than 160 GB, use the AWS CLI, AWS SDK, or Amazon S3 REST API” bu mesajda yükleyeceğimiz dosya 160GB’den büyükse bunun için AWS CLI,AWS SDK veya S3 REST API kullanmamızı öneriyor. Add files diyerek S3 Bucket’ımıza yükleyeceğimiz dosyaları seçiyoruz.
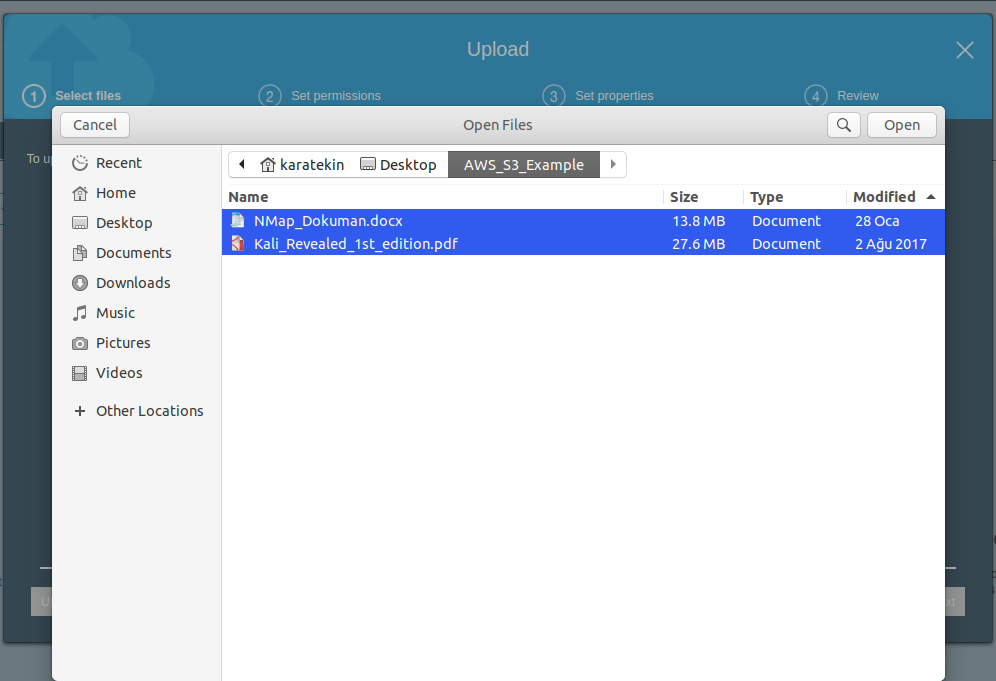
Npam ve Kali ile ilgli iki dokümanı seçtikten sonra Open diyoruz ve upload ekranına dönüyoruz. Seçmiş olduğumuz dosyalar eklenmiş oldu şimdi Next diyerek Set permissions geçiyoruz.
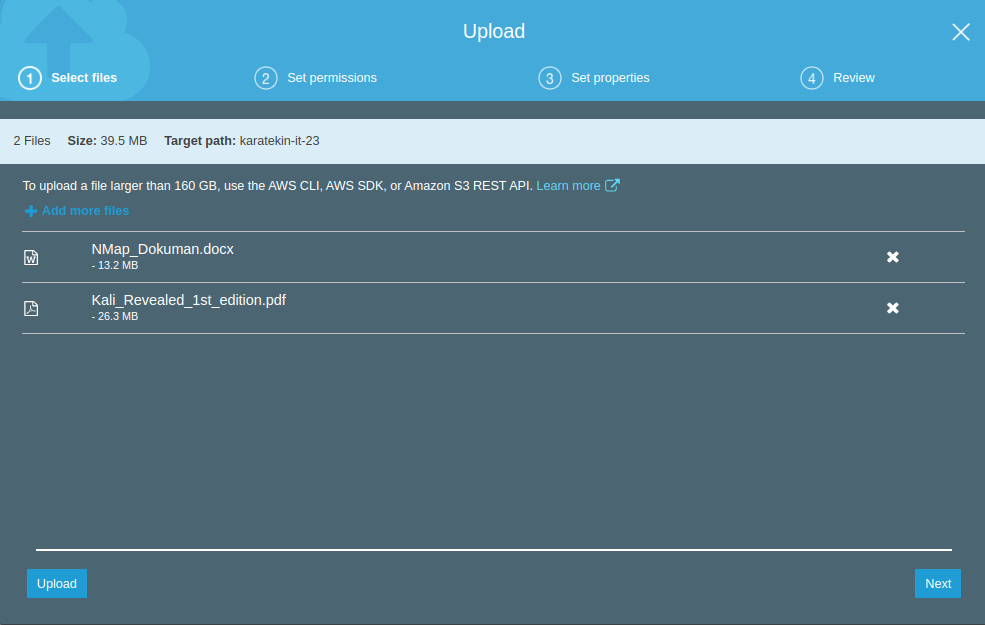
Set permissions’da bu dosyalar kimlerin erişeceğini belirliyoruz. Dosyaları biz yüklediğimiz için Owner olarak bizim Read ve Write hakkımız otomatik olarak geliyor. Access for other AWS account seçeneğinden farklı bir AWS hesabına erişim verebiliyoruz. Bu kısımda yetki verirken “arn” kullarak yetki vermemiz gerekiyor bu kısma bir sonraki uygulamada detaylı olarak anlatacağız. Manage public permissions “Grand public read access to this object(s)” seçerek dış dünyaya sadece okuma yetkisiyle bu objeleri açmış oluyoruz. Permissions işlemlerini tamamladıktan sonra next diyerek Set properties geliyoruz.
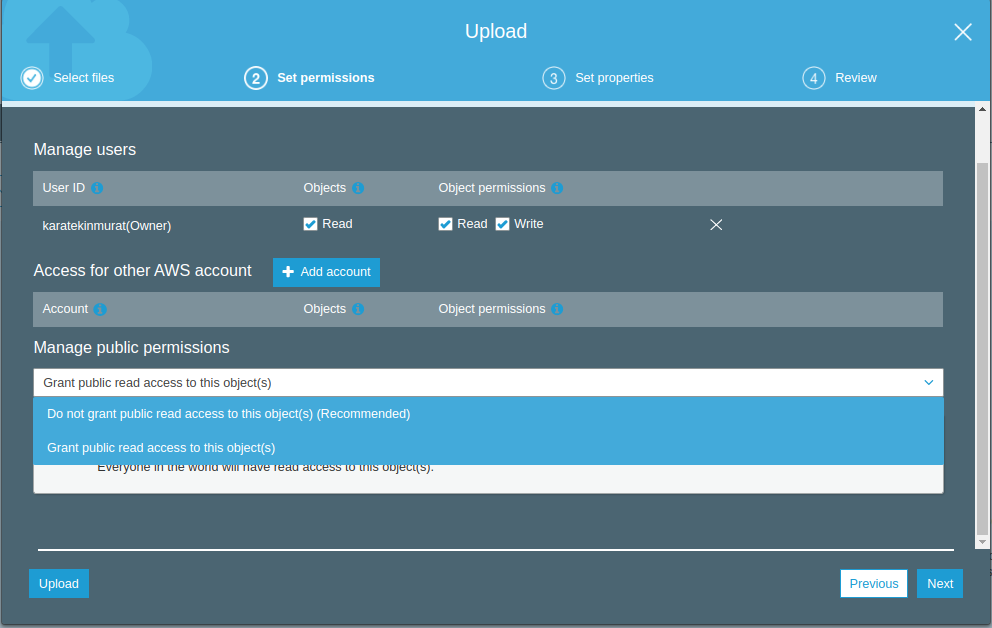
Set properties seçeneğinde bu objeler için uygun olan S3 Depolama sınıfını seçiyoruz. Bu dosyaya erişim sıklığı, kritikliği,saklama süresi gibi seçnekler gözönüne alınarak bizim için en uygun depolama sınıfını seçiyoruz. Biz S3 Standard’ı seçip Next diyerek Review geliyoruz.
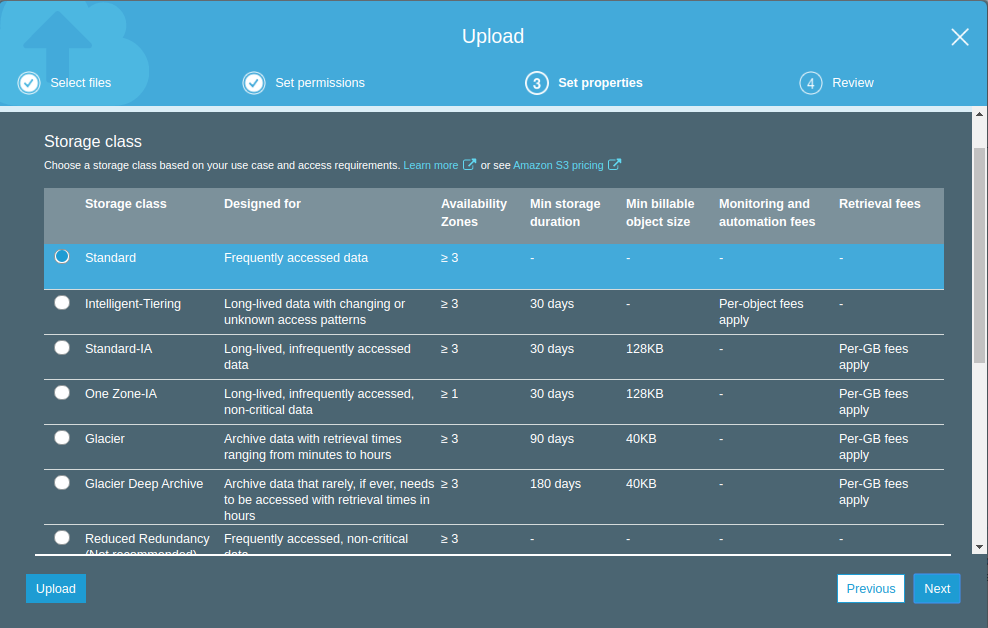
Review’de seçimlerimizin özetini gördükten sorna Upload diyerek dosyalarımızı “karatekin-it-23” isimli Bucket’ımıza yüklüyoruz.
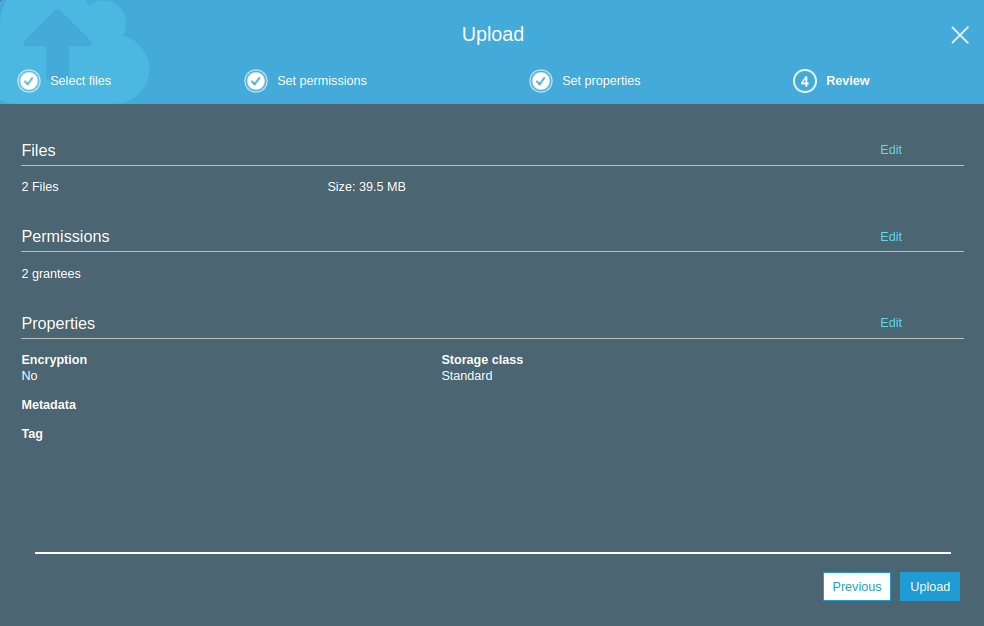
Upload işleminde sonra dosyalarımızın Bucket’a yüklendiğini görüyoruz. Bu objelere dış dünyadan erişime açmıştık şimdi dış dünyadan bu dosyalar erişip erişmediğimizin kontrolünü yaptıktan sonra basit oalrak Bucket oluşturma ve dosya yükleme konumuzu tamamlamış olacağız.
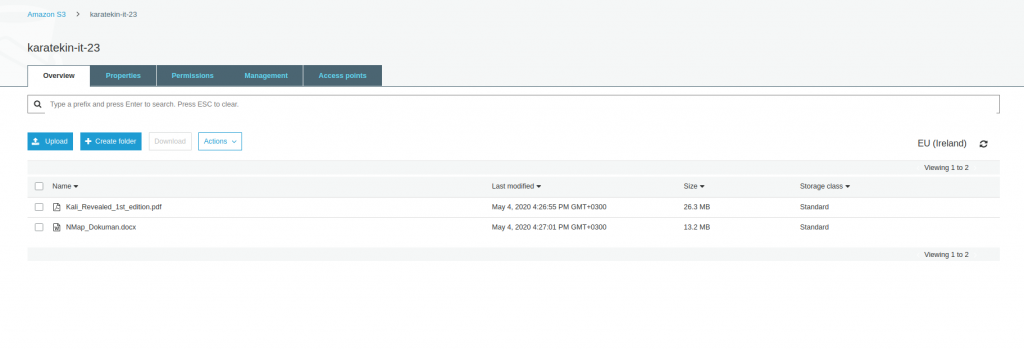
Kali ile ilgli yüklediğimiz dosyamıza dış dünyadan erişmek için dosyaye clickliyoruz. Dosya ile igli tüm özellikler karşımıza geliyor ve en altta yer alan Object URL ile bu dosayaa dış dünyadan erişebiliriz. Burada ayrıca Amazon S3 ün URL için kullandığı standar isimlendirmeyide görmüş oluyoruz. URL oluşturuken “BucketAdı.S3-Regionadı.amazonaws.com” olarak adlandırıp oluşturur.
Bucket adımız: karatekin-it-23
Servis alındığı Region: s3-eu-west-1 (İrlanda regionın kodu eu-west-1)
https://karatekin-it-23.s3-eu-west-1.amazonaws.com/Kali_Revealed_1st_edition.pdf
Url browserdan açtığımızda dosyanın içeriğine erişmiş oluyoruz. Böylece AmazonS3’te bucket oluşturma, bucketa dosya yükleme ve dış dünya ile paylaşmayı basit olarak görmüş olduk.
AMAZON S3 UYGULAMA2
Uygulamamıza başlamadan önce ARN’dan (Amazon Resource Name) bahsedeceğim. ARN AWS kaynaklarını benzersiz bir şekilde tanımlar. IAM politikaları, Amazon İlişkisel Veritabanı Hizmeti (Amazon RDS) etiketleri ve API çağrıları gibi tüm AWS’de net bir kaynak belirtmeniz gerektiğinde ARN’ye ihtiyacımız var. Servisler bir biriyle konuşurken özellikle ARN ihtiyaç duyar.
Amazon S3’de Bucket’tan ARN almanın en kolay yolu ilgili Bucket’ın simgesine (ismine değil) clikledikten sonra sağ üstte Copy ARN demek yeterlidir. Bizim oluşturudğumuz “karatekin-it-23” Bucket’ın ARN tanımı “ arn:aws:s3:::karatekin-it-23” şeklindedir.
BUCKET’A DEPOLANAN OBJELERIN OZELLIKLERI
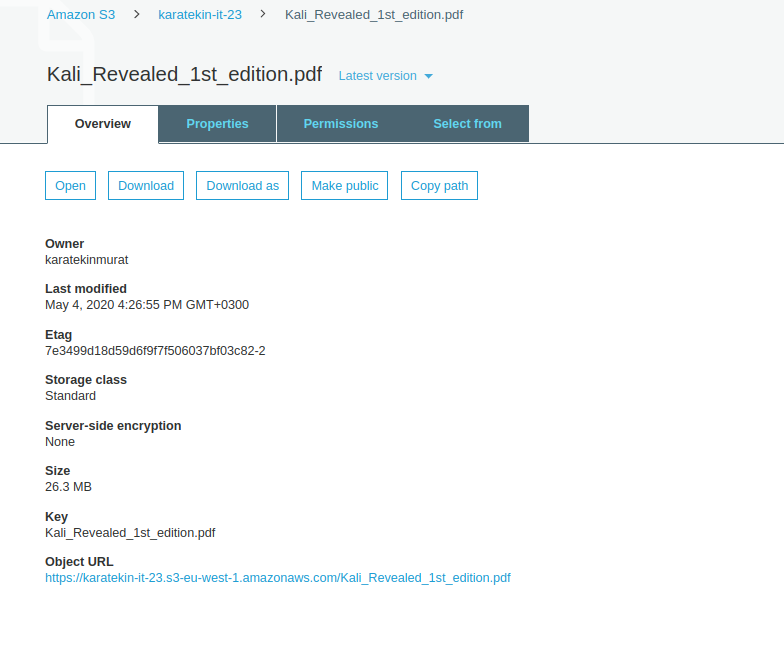
Uygulamamızda öncelikle Bucket’a yüklediğimiz objemizin özelliklerine bakacağız. Kali_Revealed_1st_edition.pdf clicklediğimizde aşağıdaki seçenekler karışımıza gelmektedir. Overview alanında objemiz hakkında en son değiştirilme zamanı, hangi storage classta depolandığı, objenin boyutu ve dışarıdan erişim URL görebilioruz. Şimdi Properties seçeneğine göz atalım.
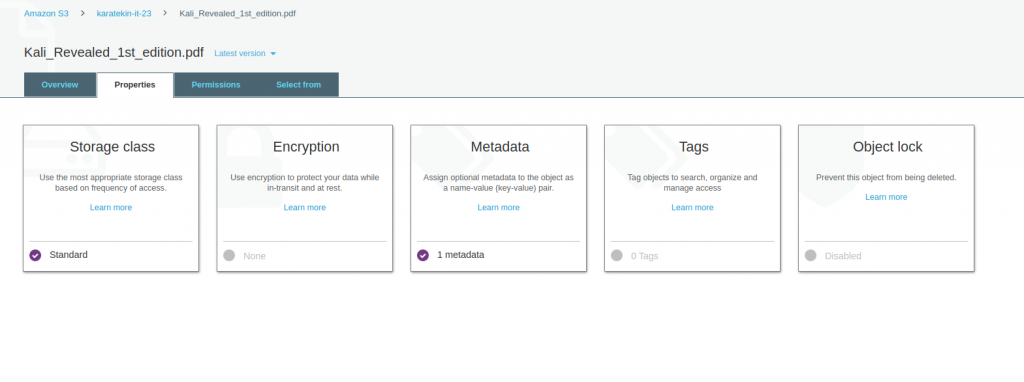
PROPERTIES
Properties seçeneğinde karşımıza Storage class, Encrytion, Metadata,Tags ve Object lock seçenekleri gelemektedir. Bu seçeneklere tek tek göz atalım.
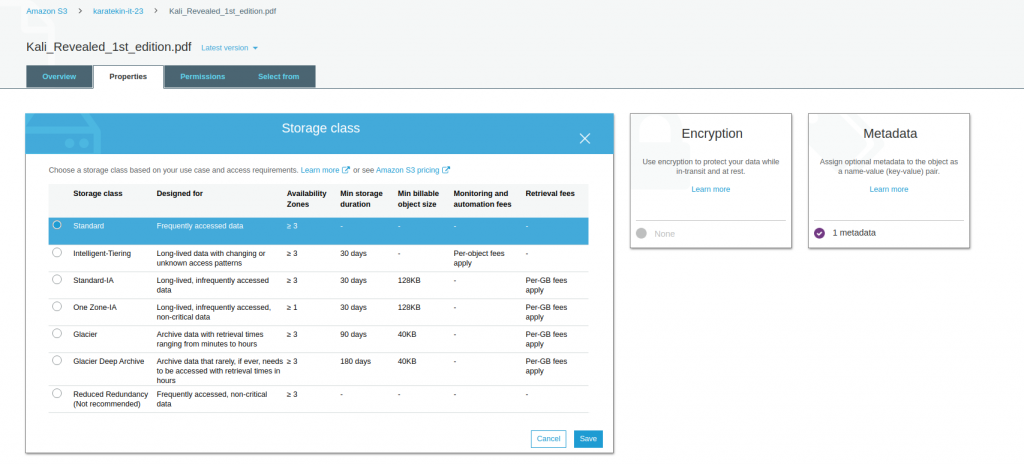
- Storage Class; Bu seçenekte bu objeyi hangi Storage Class’ta (katman) saklamak istediğimizi seçiyoruz ve save ederek geçişi sağlıyoruz. Objeyi ilk upload ederken bunu seçiyoruz ancak daha sonra bu objenin daha farklı bir katmanda depolanmasını istiyorsak buradan değiştirebiliyoruz. Storage Classes farklı özelliklerde size objelerinizi depolama imkanı sunmaktadır.
- Objelerin depolama katmanını değiştirmek için bu şekilde yapmak oldukça zaman alıcı ve karmaşık olacağı için bunu S3 Lifecycle ile Bucket seviyesinde yönetiyoruz. Bucket özelliklerinde bu konuya değineceğiz.
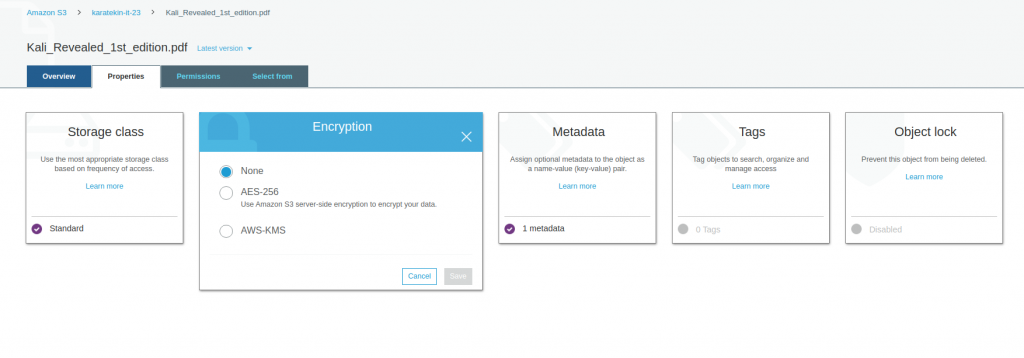
- Encryption; Adından da anlaşılacağı üzere objemizi şifreli bir şekilde saklammızı sağlar. Burada iki seçenek mevcut birisi AES256 diğeri ise AWS-KMS’dir ( Key Management Service). AES256 Amazon S3 server-side şifrele yöntemidir siz anattarlama-şifreleme mekanizmasının yönetimiyle ilgilenmezsiniz. AWS-KMS ( Key Management Service) kendi anahtarlarınızı oluşturarak objeleri şifrelemenizi sağlar.
- Metadata;Obje hakkında tutulan verilere metadata diyebiliriz. Metadata son kullanıcı için birşey ifade etmeyebilir ancak özellikle geliştiriciler Metadataları kullanarak geliştirme yapabilir. Metadatayı seçtiğimizda AmazonS3’ün obje hakkında yazdığı metadataları görebilirsiniz ayrıca sizde objeyle ilgili manuel tanım yapmak isterseniz Add Metadata ekleyebilirsiniz.
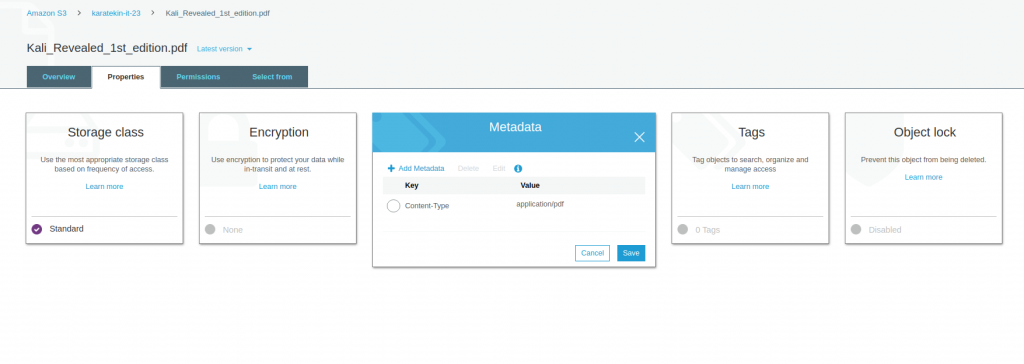
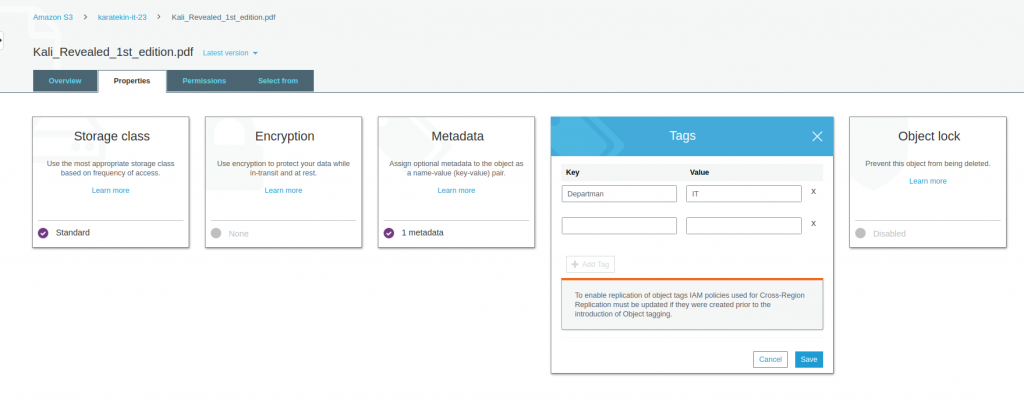
- Tags; Tags iki değerden oluşur Key (anahtar) ve Value(değer) burada objeyle ilgili bir tag belirleyebiliriz. Örneğin bu objemize key(anahtarı) departman, value(değeri) it olan bir tag belirleyelim. Objeleri bu şekilde etiketlediğimizde örneğin ay sonunda hangi departmanın ne kadar verisinin S3’te depolandığını ve bu depolama için departman bazında ne kadar ücret ödediğimizi görmemiz mümkün olur.
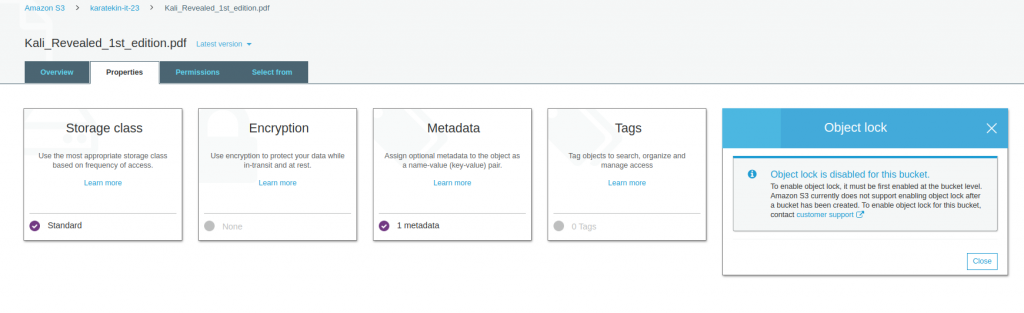
- Object lock; Bu özelliği obje bazında kullanamıyoruz. Bucket’ın özelliklerinde devreye alabiliyoruz. Kısaca bu özellik Bucket’ta devreye alınırsa Bucket’a yüklenen verilerin erişenler tarafından silinmesini engeller bu yanlışlıkla verilerin silinmesini önüne geçerek kouruma sağlamış olur.
PERMISSIONS
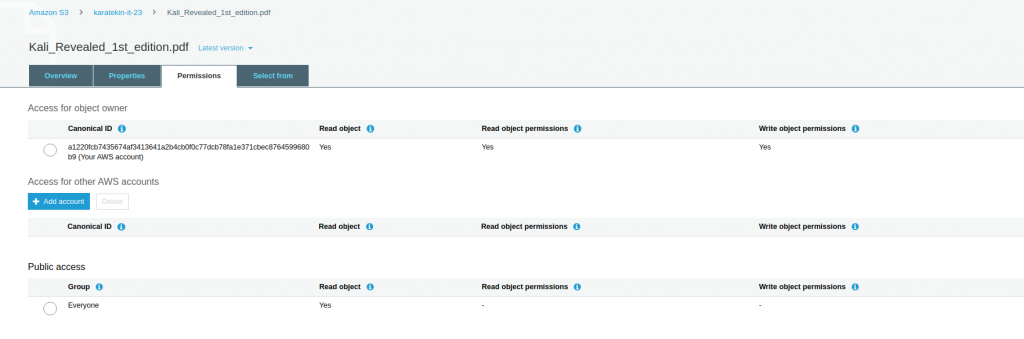
Objenin permissions seçeneklerine;
- Access of object owner: Objeyi oluşturan hesabın yetkilerini değiştirmek için kullanılır.
- Access for other AWS accounts: Başkabilir AWS hesabının objeye erişmesine izinvermek için kullanılır.
- Public access: Dış dünyadan bu onjeye erişim sağlanması için kulanılır. Biz dışarıdan Everyone (herkes) için sadece Read hakkı verdiğimizi burada görebiliyoruz.
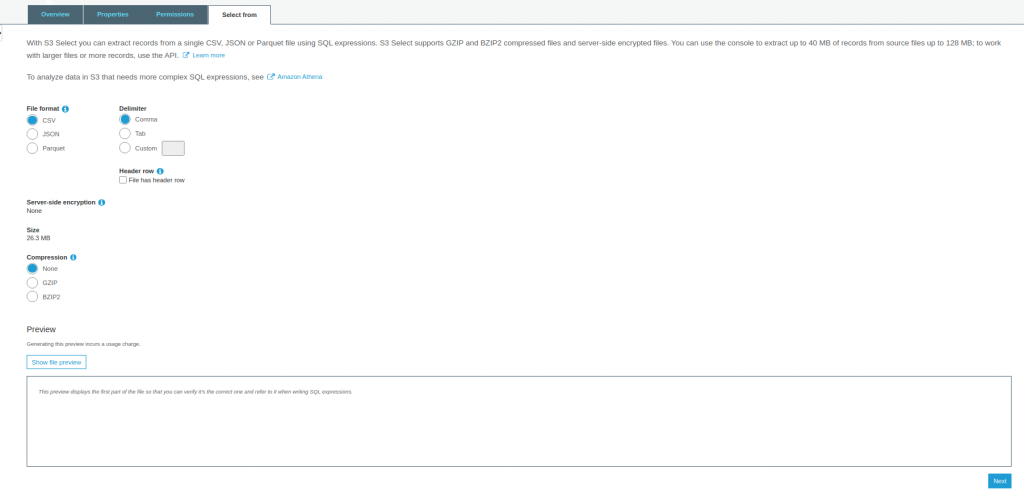
SELECT FROM
S3 Select ile SQL ifadelerini kullanarak tek bir CSV veya JSON dosyasından kayıtları çıkarabilirsiniz. AmazonS3 bu yönde gelen yoğun talepler sonucunda S3’te depolnana logdosyaları, cvs ve json dosyalarında sorgulama yapmaya olanak sağlamıştır.
BUCKET’IN OZELLIKLERI
Objenin özelliklerini gördükten sonra şimdide Bucket’ın özelliklerini ve neleri yapabileceğimize gözatacağız.
OVERVIEW
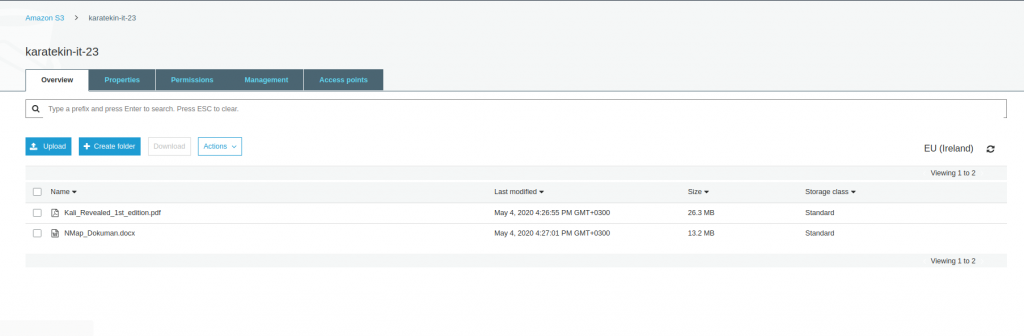
Bucket’a doya upload ettiğimiz, klasör oluşturduğumuz ve bucket’a yüklenen dosyaları görüntülediğimiz alandır. Actions ile seçilen objeyle ilgili işlemler yapılır. Örneğin objenin boyutu, özelliklerinin değiştirilmesi, download edilmesi gibi.
PROPERTIES
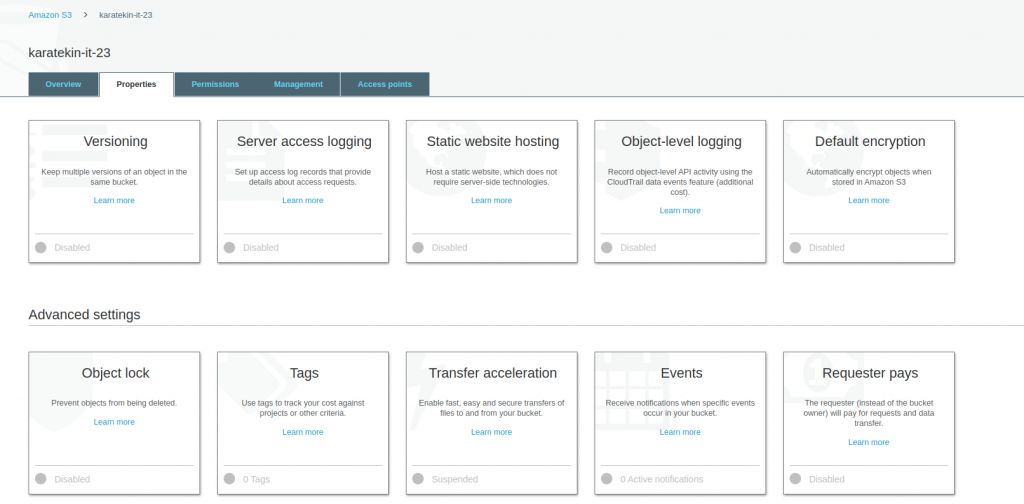
Oluşturuduğumuz Amazon S3 Bucket’ına ekleyebileceğimiz özellikleri yönettiğimiz yerdir. Biz işlemlerimizi oluşturmuş olduğumuz “karatekin-it-23” isimli Bucket için yapıyoruz.
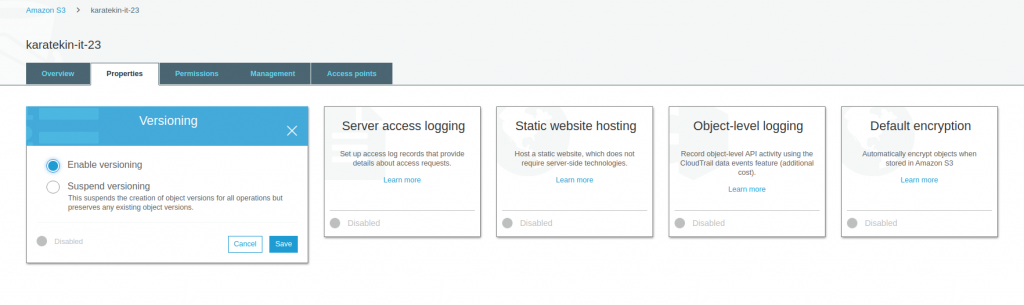
- Versioning; Bucket içinde versiyonlama yapmamıza imkan verir. Versiyonlamayı bir kez aktif hale getirdiğinizde artık devre dışı bırakamıyorsunuz sadece durdurabiliyorsunuz. Versiyonlama bir objenin birden fazla sürümünü saklamak için kullanılır. Örneğin siz bir dosya yüklediniz ve bir süre sonra bu dosyanın içeriğini değiştirip tekrar Bucket’a attınız, versiyonlama (versioning) enable ise yüklediğiniz dosyanın son halini göründüler ancak bir önceki halinide ihtiyacımız olduğunda geri dönebilmemiz için saklar buna versiyonlama diyoruz. Uygulamalı olarak gösterelim öncelikle Versioning Enable dedikten sonra save edelim.
- Versioning Enable ettik şimdi öncelikle bucket’a karatekin.txt adından bir dosya yükleyeceğiz daha sonra yüklediğimiz dosyanın içeriğini değiştirerek tekrar bucket’a yükleyeceğiz. Versiyonlama devrede olduğu bu sürecin nasıl çalıştığını göreceğiz.
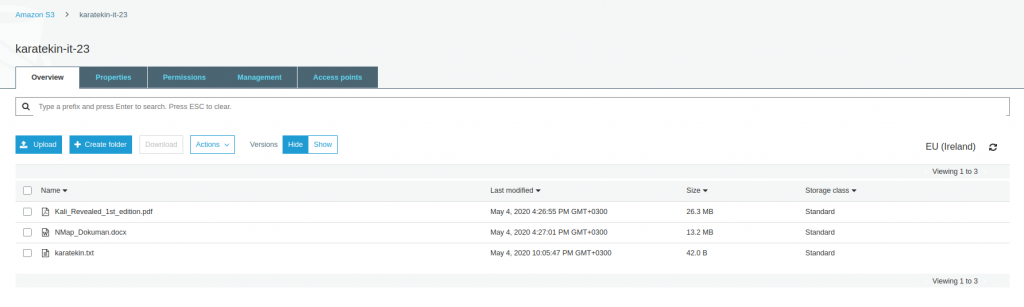
- karatekin.txt dosyasını Bucket’a yüklemiş olduk. Yükleme sırasında public access enable ederek dış dünyaya açtık. Bu işlemleri S3 için yaptığımız ilk uygulamada gösterdiğimiz için burada tekrar etmeyeceğiz. Şimdi dışarıdan karatekin.txt erişmek için URL kullanalım https://karatekin-it-23.s3-eu-west-1.amazonaws.com/karatekin.txt

- Gördüğünüz gibi karatekin.txt dosyamızı bucket’a upload ettik ve dış dünyadan erişim sağladık. Şimdi karatekin.txt dosyasına bir satır daha ekleyeceğiz ve tekrar upload ederek versiyonlamanın nasıl çalıştığını göreceğiz.
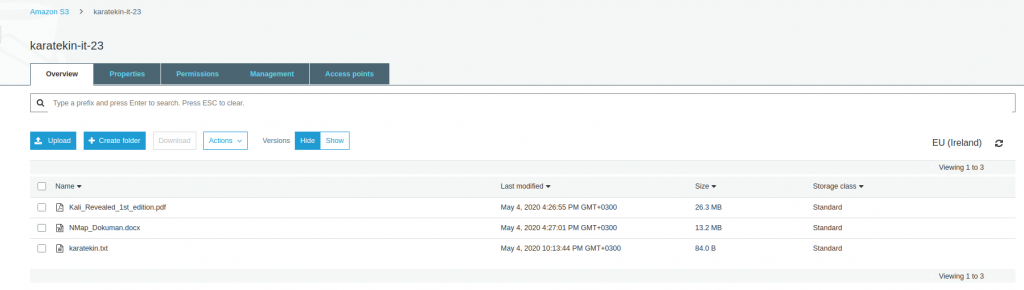
- karatekin.txt upload ettik ve dosyanın değiştirildiğini gördük. Tekrar dış dünyadan erişmek için URL kullandığımızda içeriğin değiştiğini göreceğiz. https://karatekin-it-23.s3-eu-west-1.amazonaws.com/karatekin.txt

- Versiyonlamanın çalıştığını görmek için Overview ekranına eklenen “Versions Hide/Show” seçeneğini Show olarak seçtiğimizde dosyalarımızın tüm versiyonlarının görüntülendiğini göreceğiz. Latest Version en güncel ve bize görüntülenen haliyle birlikte tüm versyonlar dosyaların altında listelenir.
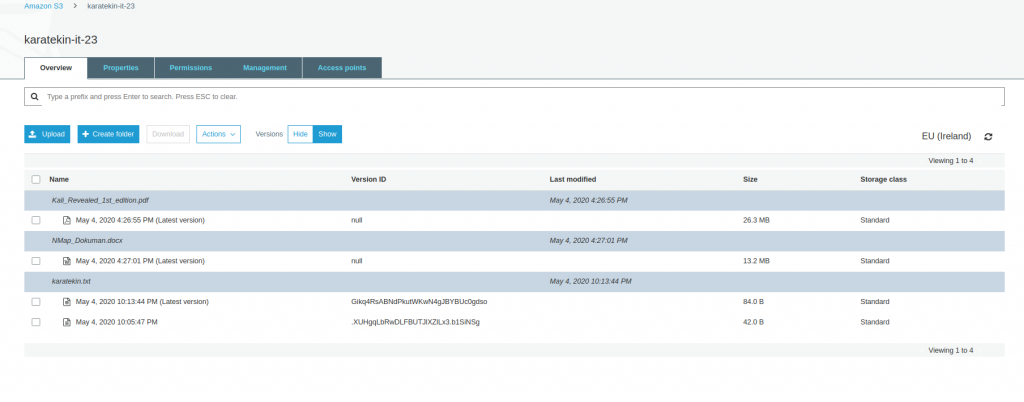
- Versiyonlama sayesinde dilerseniz eski versiyonu download edebilir yada url üzerinden içeriğine erişebilirsiniz.
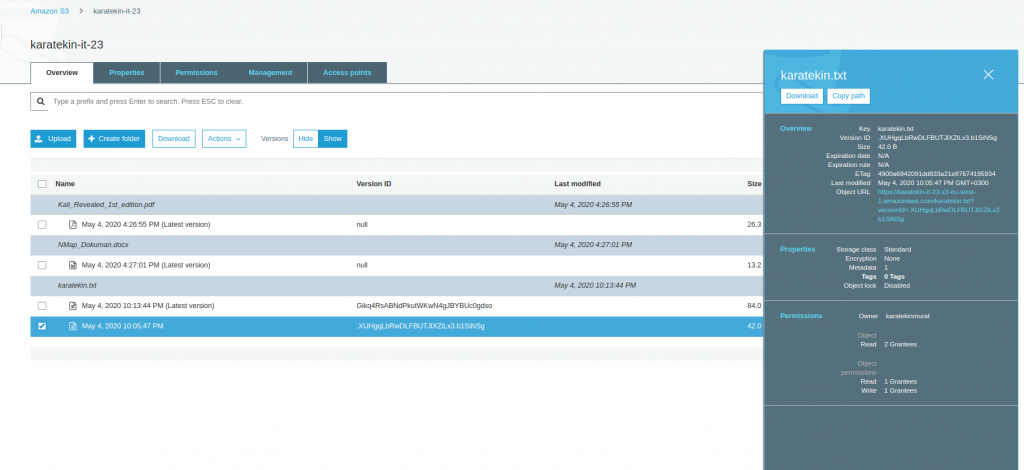
- Versiyonlama bize aynı zamanda dosyayı yanlışlıkla silmemiz durumuda tekrar kurtarma şansı verir. Siz dosyayı sildiğinizde versiyonlama dosyaya bir “ Delete marker” silme işareti koyar ve siz dosyayı göremezsiniz. Versions Show dediğimizde sildiğimiz dosyanın “delete marker” işaretini kaldırdığımızda tekrar erişebilir duruma geliriz. Versionlama bu nedenle son derece önemlidir ve mutlaka sık kullandığımız verilerin bulunduğu bucketlarda enable etmemiz gerekir. Şimdi karatekin.txt dosyasını silelim ve versiyonlamanın nasıl davrandığını ve tekrar nasıl geri yüklediğimizi görelim. Karatekin.txt dosyasını seçip Actions’tan Delete diyoruz. Silme işlemini gerçekleştirdikten sonra Versions Show diyerek bucket dosyalarımızı listeliyoruz.
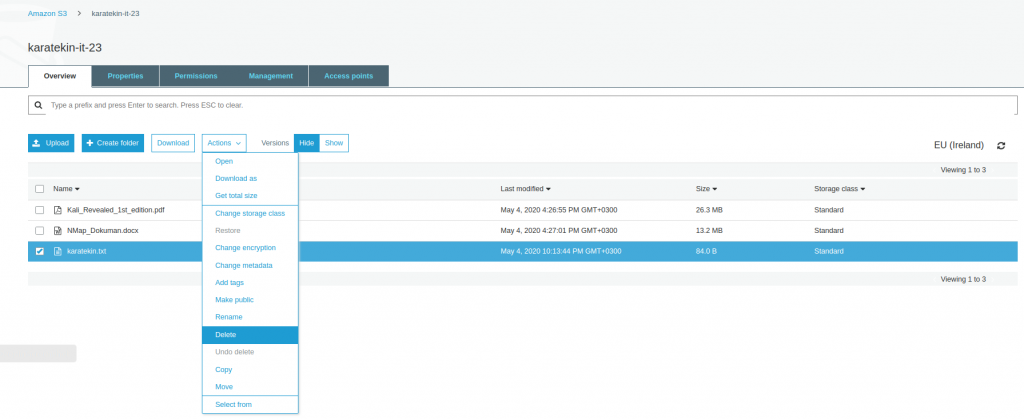
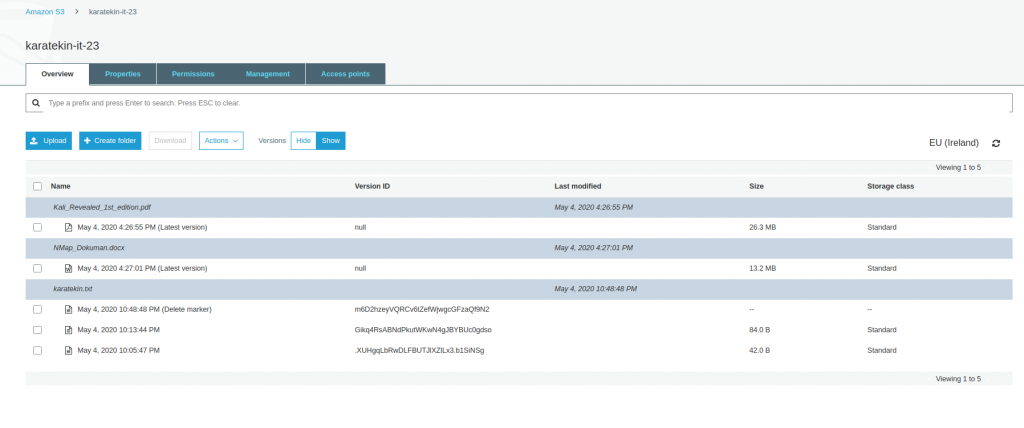
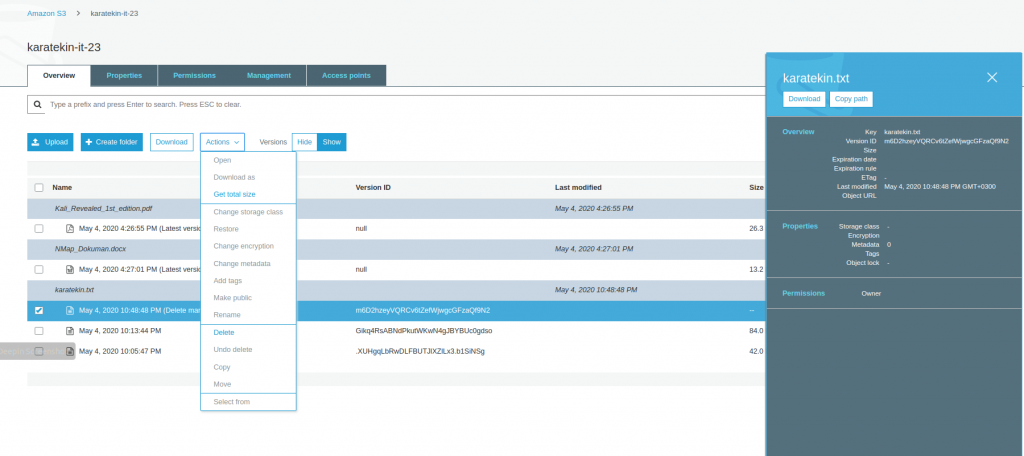
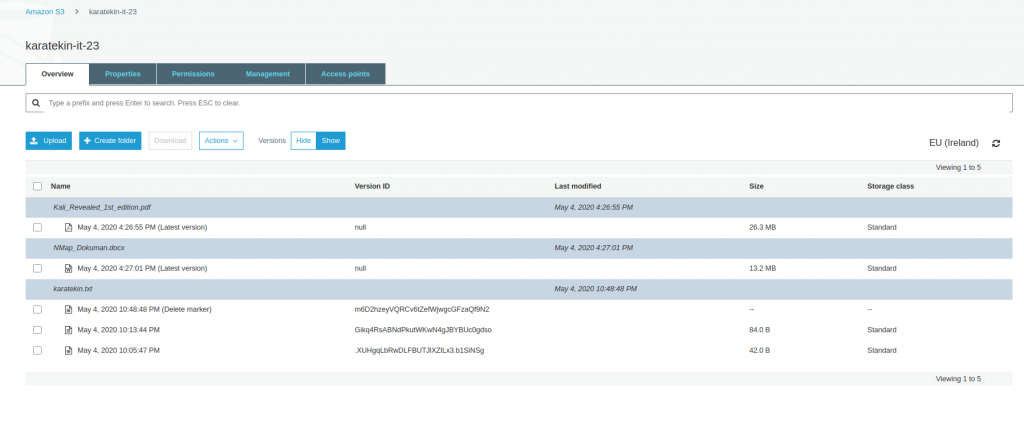
- Gördüğünüz gibi sildiğimiz karatekin.txt dosyasının tüm versiyonları listelendi ve sildiğimiz en güncel halide “Delete marker” ile işaretlendi. Şimdi “Delete marker” olan versiyonu seçerek Actions’tan Delete diyeceğiz böylece dosyayı tekrar Bucket’ta son haliyle erişilebilir duruma getireceğiz. Versiyonlama ile ilgli uygulamamızı tamamlamış olacağız
- Server Access Logging; Bucket içine koyduğumzu dosyalara yapılan tüm erişimlerin loglarını tutmak için kullanılır. Burada dikkat edilmesi gereken nokta log dosyalarını da loglama yapacğaı Bucket’ın içine yazarsanız Bucket’ın kapasitesi büyüyecektir. AWS bu tip işlemler için ayrı bir bucket tanımlayarak logları bu bucketa yazmamızı önerir. Bizde “bucket-log-karatekin” adında bir Bucket oluşturarak logların buraya yazılmasını sağlayacağız. Bucket oluşturmayı anlatığımız için bu kısmı geçerek doğrudan Server Access Logging ayarlarına geçiyoruz. Target bucket olarak oluşturduğumuz log Bucket’ını seçiyoruz, Target prefix alanıda istersek loglarımızı belirlediğimiz prefixle kaydetmesini sağlayabiliriz örneğin attığı tüm log dosyalarını bucketlogkaratekin olarak kaydedeblir. Save ettikten sonra devreye almış oluyoruz. Bucket’ın içinde yer alan bir kaç dosya üzerinde işlem yaparak log oluşmasını sağlayacağız.
Log dosyalarımız oluştur ve log için oluşturduğumuz bucket’a yazılmaya başladı. Hemen alta yazılan bir log dosyasının içeriğini bulabilirsiniz.
- Static website hosting; AWS statik web sayfalarınızı AmazonS3’te host etmenizi sağlıyor. Web sayfanız statikv e kullanıcı etkileşimli bir sayfa değilse AmazonS3’te oluşurduğunuz Bucket’ta depolayabilirsiniz. Biz oluşturduğumuz statik sayfanın index.html, error.html ve vader.jpg dosyasını “karatekin-it-23” isimli Bucket’a upload ederek statik sayfamızı çalıştırıyoruz. Erişim için http://karatekin-it-23.s3-website-eu-west-1.amazonaws.com URL kullanıyoruz. Ayrıca “Redirect requests” ile url istediğimiz websitesine yönlendirebiliriz. Şimdi statik sayfamıza URL üzerinden erişelim.

Sayfamız başarılı bir şekilde yayınlandı.
- Default encryption; Bir önceki konuda objeler için şifreleme işlemini anlatmıştık burada farklı olan tek şey Bucket için aktif ettiğimizde Bucket’a atılan tüm objelere bu şifreleme işlemini uygular ve tek tek objeler için uğraşmak zorunda kalmayız. Ayni şekilde AES256 server-side ve AWS-KMS’i kullanarak gerçekleştirebiliriz.
- Object lock; Oluşturduğunuz bir Bucket’a atılan dosyaların silinmemesine ihtiyacınız varsa, örneğin yasal bir süre boyunca saklamanız gereken dosaylar var ve silinmemesi gerekiyor bu tip durumlarda Object lock’ı devreye alırız. Aşağıda uyarıda da göreceğiniz gibi oluşturulmuş bir Bucket’ta Object lock’ı devreye alamıyoruz. Bucket’ı ilk oluşturma sırasında gelişmiş ayarlarda Object lock’ı enable ederek Bucket’ı oluşturmamız gerekiyor.
- Transfer acceleration; Oluşturduğumuz Bucket’ın içinde büyük boyutlu bir dosya atmaya çalıştığımızda daha hızlı bir şekilde dosyanın transferini sağlamak için kullanırız. Örneğin 1TB bir dosyayı oluşturmuş olduğumuz Bucket’a atmak istiyoruz. Bucket İrlanda region oluşturulmuş olsun ve biz dosyayı Türkiye’den İrlanda’da bulunan S3 Bucket’ımıza atmaya kalktığımızda örneğin bize transferin 18 saat süreceğini düşünelim işte Transfer acceleration daha hızlı bir şekilde bu transferi gerçekleştirmek için bir endpoind tanımlar ve bu endpoint üzerinden Amazon’un CDN ( Contend Delivery Network) alt yapısını kullanarak dosyayı daha hızlı bir şekilde Bucket’a transfer eder. Bu işlem içinde extra ücret alır, eğer zaman kritik bir dosya transfer işlemimiz varsa Transfer acceleration kullanabiliriz. Enable ettiğiğimizde bir daha disable edemiyoruz sadece Suspended (geçici olarak durdurma) edebiliyoruz. Transferi hızlılandırmak için karatekin-it-23.s3-accelerate.amazonaws.com endpoint kullanarak gerçekleştirir.
- Events; AmazonS3 Bucket’ında yaptığınız bir işlemin başka bir AWS hizmetinde bir işi tetiklemesini istiyorsak Events kısmını kullanabilirsiniz.
- Requester pays; Amazon hatırlarsanız S3 hizmetini ücretlendirirken dowload edilen objeler içinde bir ücret alıyordu, işte bu servis oluşturduğunuz Bucket’a erişip buradaki objeleri download eden başka bir AWS hesabıysa bu download ücretini indiren AWS hesabına faturalanmasını sağlıyorsunuz. Burada önemli bir uyarı Enable ettiğinizde public access disable olur ve anonim erişimler engellenir.
MANAGEMENT
- Lifecycle; AmazonS3 katlamanlarından bahsederken bu katmanlar arasında objelerimizi taşırken bu işlemi yazacağımız kurallarla otomotize edebileceğimizi belirtmiştir. İşte Lifecycle’da yazacağımız rulelarla bir objeyi S3 Standart katmandan S3 Standart IA veya S3 Glacier taşıyabiliriz. Add lifecycle rule diyerek nasıl yapıldığını görelim.
Name and scope: Bu alanda lifecycle kuralımız için bir isim veriyoruz. Choose a rule scope seçeneklerinden Limit the scope specific prefixes or tags seçeneğini seçersek belirlediğimiz öndeğerler(prefix) ve etiketleri(tags) taşıyan objeler için bu kuralı uygular. Apply to all objects in the bucket seçersek Bucket içinde bulunan tüm objelere bu kuralı uygular. Biz Apply to all objects in the bucket seçerek next diyoruz.
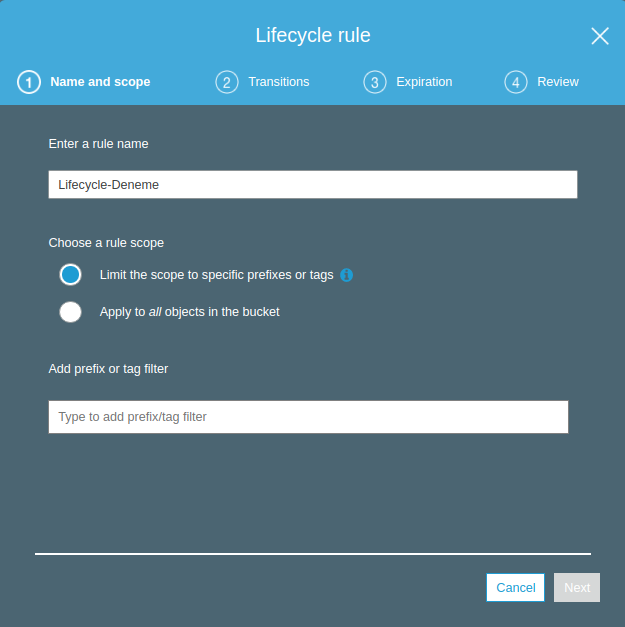
Transitions : Objelerin hangi versiyonlarının hangi storage katmanlarına taşınacağını burada belirliyoruz. Biz Current version (şuandaki versiyon) için oluşturulduktan 45 gün sonra S3 Standard-IA’e taşımasını, Previous versions ( geçmiş versiyonlar) için de oluştuktan 90 gün sonra S3 One Zone-IA’e taşınması için ayarlamamızı yaptık. Bucket içindeki tüm objeler bu kuralla göre ilgili katmanlara taşınarak maliyetimizi optimize etmiş olacağız. Next diyerek Expiration seçeneğine geçiyoruz.
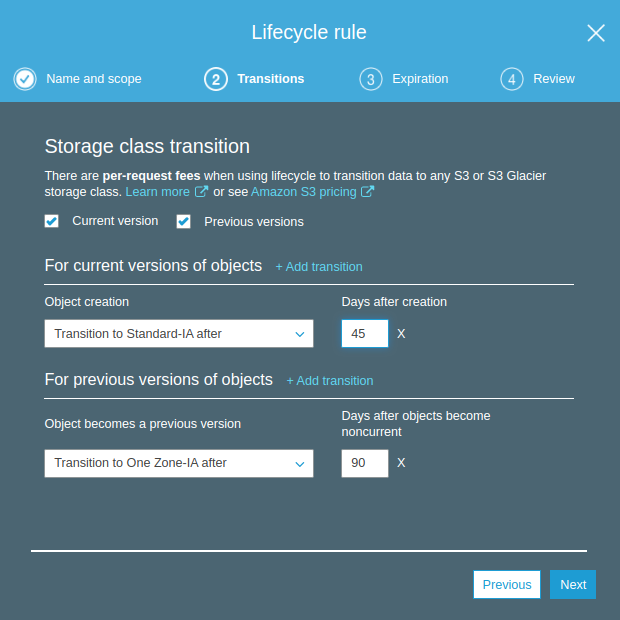
Expiration: Objelerin Current ve Previous versiyonları için belirlediğimiz sürlerden sonra objelerin silinmesi için gerekli ayarlamaları yapıyoruz. Biz Current version için objenin oluşturma tarihinden itibaren 410 gün geçmişe silinmesi, aynı şekilde Previous versions içinde 455 gün sonra silinmesi için ayarıız yaptık. Clean up expired seçeneğinde eğer tamamlanmamış multipart uploadlar varsa ve üzerinden 15 gün geçmişse bunlarında silinmesi için gerekli ayarı yaptık. Clean up expired object delete markers ise disable durumda çünkü Current versionları silmek için ayar yaptığımız için delete markerslarda siliniyor olacak. Next diyeren Review geliyoruz.
Review: Tanımlarımızın bir özetini gödükten sonra bu kuralın Bucket içindeki tüm objelere uygulanacağını anladığımızı belirten onayıda verip save diyoruz.
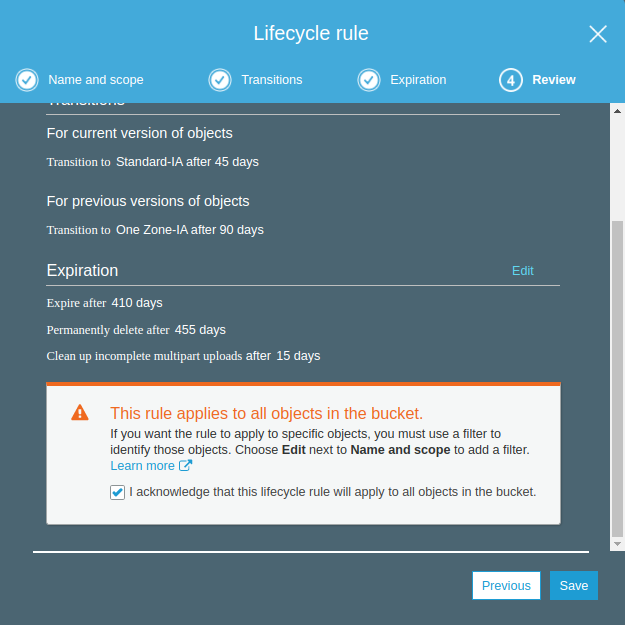
Böylece karatekin-it-23 Bucket’ı için bir Lifecycle kuralı tanımlaış olduk.
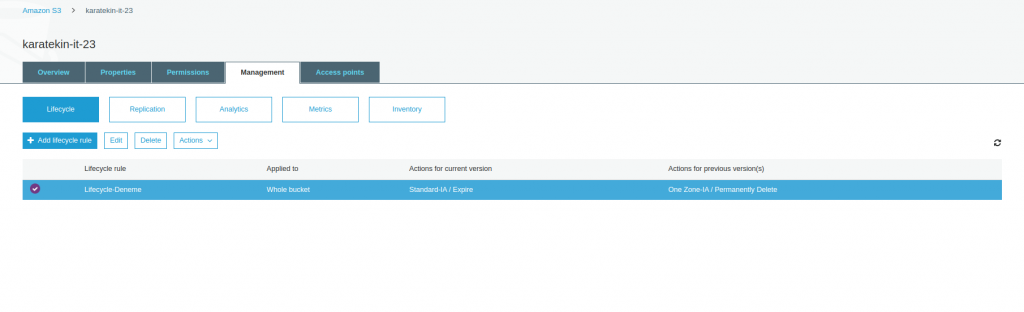
- Replication: Bucket’ı başka bir regionda oluşturduğumuz bucket’a replike etmek için kullanırız buna Cross-Region Replication denir . Böylece regionlardan biridne sorun olması durumunda diğer regiondan erişim sağlayabiliriz. Kritik verilerimiz için coğrafi yedeklilik sağlamak için kullanılabilir. Kural tanımlama sihirbazı Lifecycle benzer olduğu için görsel eklemeyeceğiz.








Eline sağlık, kitap gibi makale olmuş.
Teşekkürler Üstad, eylemlerim devam edecek. 🙂