Amazon S3, Önizlemede Gelişmiş Veri Yönetimi ve Sorgulama için Meta Veri Özelliğini Tanıttı!
Amazon Web Services (AWS), veri keşfi ve yönetimini kolaylaştırmak için yeni bir özellik olan Amazon S3 Metadata’yı tanıttı. Şu anda ABD East (Ohio ve N. Virginia) ile ABD West (Oregon) bölgelerinde ön izleme aşamasında sunulan bu özellik, kullanıcıların S3 verilerini daha etkin bir şekilde sorgulayıp analiz etmesini sağlıyor.
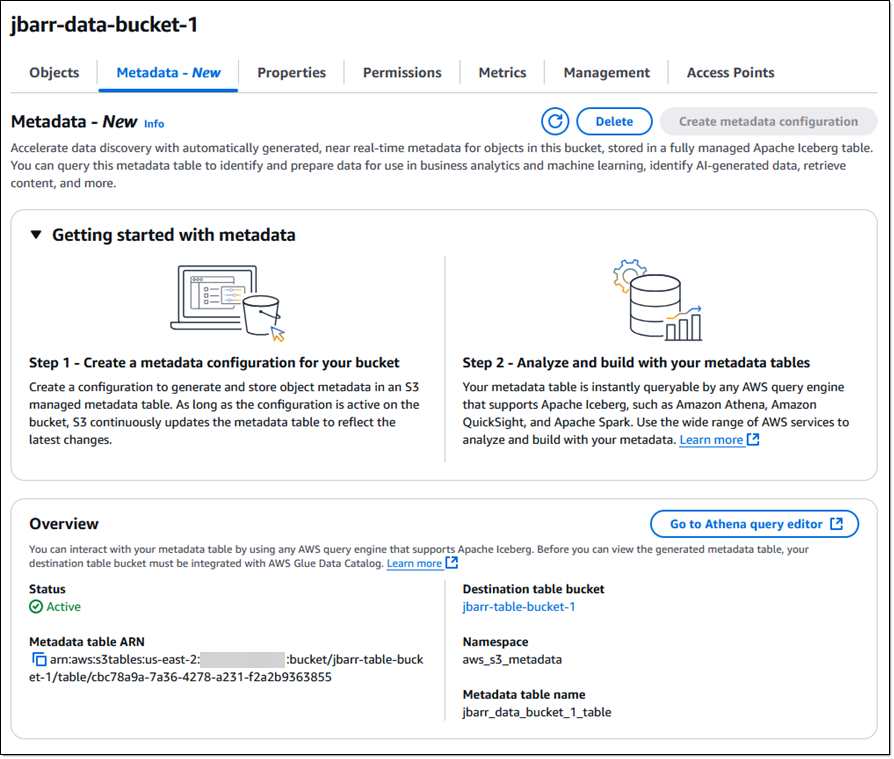
Amazon S3 Metadata Nedir?
Bu yeni özellik, S3 nesnelerine ait meta verileri otomatik olarak toplayarak sistem tanımlı özellikler (boyut, depolama sınıfı, şifreleme durumu) ve kullanıcı tanımlı etiketler gibi bilgileri düzenliyor. Böylece işletmeler, verilerini şu alanlarda daha verimli kullanabiliyor:
- İş analitiği
- Gerçek zamanlı çıkarım uygulamaları
- Yapay zeka modeli eğitimi
Amazon S3 Metadata, nesnelerde yapılan değişikliklerden birkaç dakika sonra meta verileri güncelleyerek neredeyse gerçek zamanlı bir doğruluk sağlıyor. Bu veriler, S3 Tables adlı yeni bir kova türünde saklanıyor ve Apache Iceberg teknolojisi ile uyumlu olarak işleniyor.
Apache Iceberg Entegrasyonunun Avantajları Nelerdir?
Apache Iceberg sayesinde meta veriler, Iceberg tablolarında saklanarak ölçeklenebilir ve yüksek performanslı sorgulamalara olanak tanıyor. Bu yapı, şu araçlarla tamamen uyumlu:
- Apache Spark
- Amazon Athena
- Amazon QuickSight
Iceberg’in sunduğu özelliklerden biri, her güncellemenin tabloya yeni bir satır eklemesi. Bu durum, S3 nesnelerindeki değişikliklerin geçmişinin detaylı bir şekilde analiz edilmesini mümkün kılıyor. Amazon S3 Metadata, AWS analitik araçları ile sorunsuz bir şekilde entegre oluyor. Öne çıkan entegrasyonlar şunlardır:
- AWS Glue Data Catalog (ön izleme aşamasında)
- Amazon Athena, Redshift, EMR ve QuickSight ile meta veri sorgulama
- Amazon Bedrock ile S3’te saklanan AI tarafından üretilen videoların meta verilerle zenginleştirilmesi
Meta veri şeması, kovalar ve nesne anahtarları gibi temel bilgilerden şifreleme detaylarına ve kullanıcı tanımlı etiketlere kadar 20’den fazla öğeyi içeriyor. Kullanıcılar, bu verileri uygulamaya özel tablolarla birleştirerek daha kapsamlı analizler yapabiliyor.
Bir sorgu örneği şu şekilde görünüyor:
spark.sql("SELECT key, size, storage_class, encryption_status FROM mytablebucket.aws_s3_metadata.my_table ORDER BY last_modified_date DESC LIMIT 10").show(false) Amazon S3 Metadata Nasıl Aktif Edilir?
S3 Metadata’yı etkinleştirmek için şu üç adımı izleyebilirsiniz:
- Tablo Kovası Oluşturma: AWS Yönetim Konsolu, API çağrısı veya komut satırı aracıyla bir kova oluşturun.
- Meta Veri Yapılandırması Ekleme: Veri kovasını meta veri tablosuyla ilişkilendirmek için yapılandırma dosyasını tanımlayın.
- Sorgulama ve Analiz: Apache Spark veya AWS analitik araçlarıyla meta verileri sorgulayarak detaylı içgörüler elde edin.

Amazon S3 Metadata, yapılan güncellemelerin (nesne oluşturma, silme ve meta veri değişiklikleri) sayısına ve meta veri tablosunun depolama maliyetine göre fiyatlandırılıyor. Daha fazla bilgi için burayı ziyaret edebilirsiniz.








