
SQL Server 2022 Yenilikler, Intelligent Query Processing, DOP Feedback
DOP, degree of parallelism. Bu kavram özellikle database ile uğraşanlara tanıdık gelecektir. Bir sorguda kullanılan cpu sayısına verilen isimdir. Özellikle Join, order by, group by gibi kavramlarda SQL Server cpu ları paralel şekilde çalıştırır. Tabi teorik olarak ne kadar çok işlemci o kadar çok performans ve o kadar kısa sorgu süresi denilebilir. Ama gerçekte durum tam olarak bu şekilde değildir.
Örneğin bir sorgu
1 cpu ile 8 saniyede
2 cpu ile 5 saniyede
4 cpu ile 3 saniyede geliyor olabilir.
Bu hesapla baktığımızda 8 cpu ile 1.5 saniyede 16 cpu ile 1 saniyeden az sürede gelmesini bekleyebiliriz. Ama bu şekilde mutlak bir oran yoktur.
Gelin bunu doğrulayalım.
Elimizde bir e ticaret veritabanı var. Bu veritabanından ilişkisel tablolardan veri çekiyoruz. Bu tablolar ortalama 2 milyon satır veriye sahip.
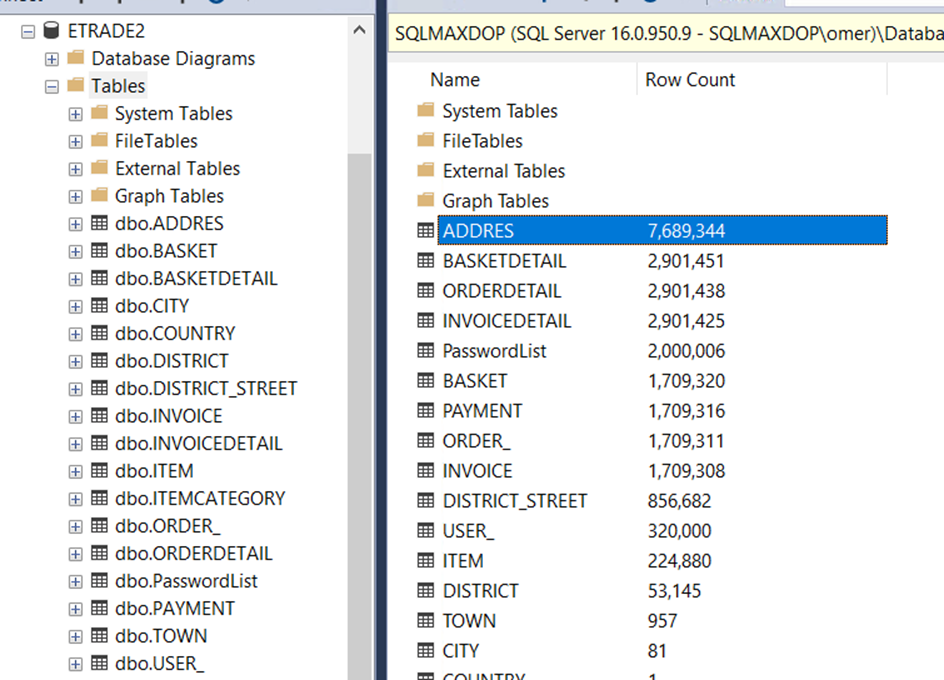

Şimdi bu veritabanı üzerinde hem join hem de group by kullanarak bir sorgu çekelim.
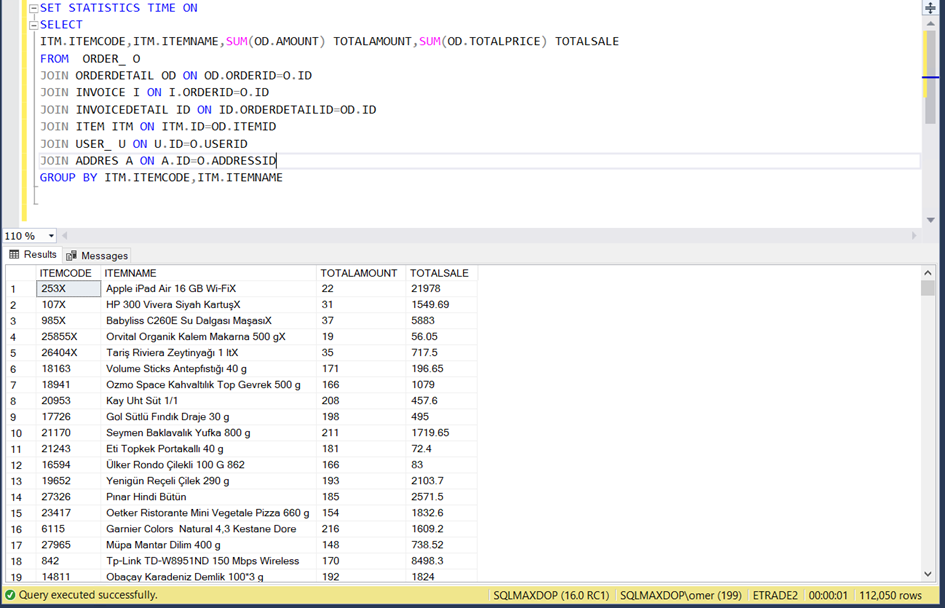
Görüldüğü gibi yaklaşık 1 sn de gelmiş durumda. Sorgunun üzerine yazmış olduğumuz SET STATISTISCS TIME ON komutu sorgunun ne kadar sürede geldiği bilgisini detaylı olarak gösterir. Messages kısmına tıkladığımızda bu sorgunun ne kadar sürede geldiğini görebiliriz.
Görüldüğü gibi sorgumuz aslında 1305 milisaniye sürmüş. Yani 1.3 sn.
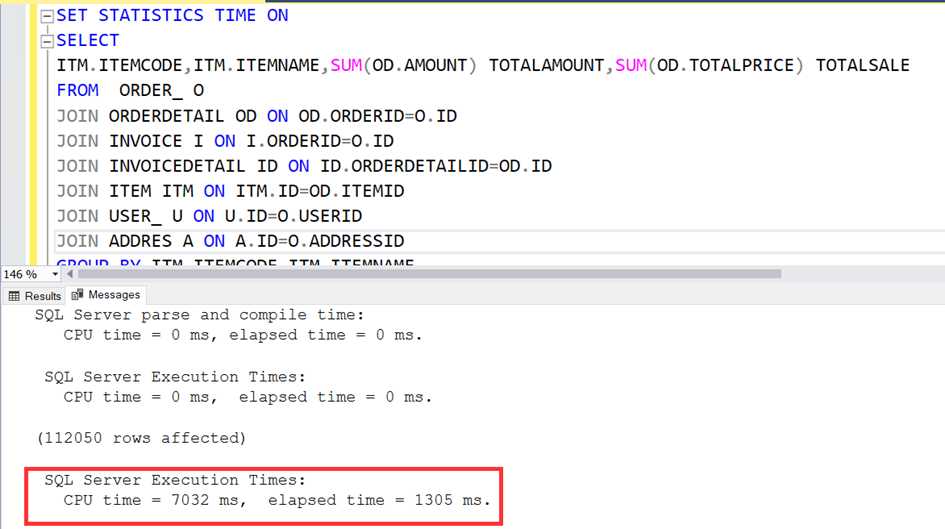
Şimdi bu işlemi yaparken ne kadar cpu kullanmış ona bakalım.
Sistem boştayken cpu ların görünümü bu şekilde. Tabiri caizse 32 cpu nun hepsi yatıyor.
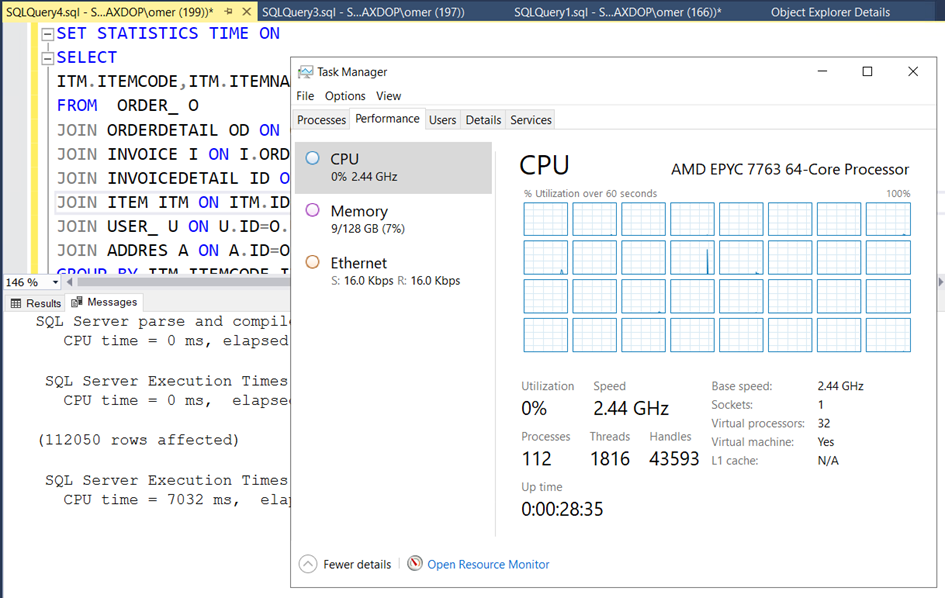
Şimdi de sorguyu çalıştırıp ekran görüntüsü alalım.
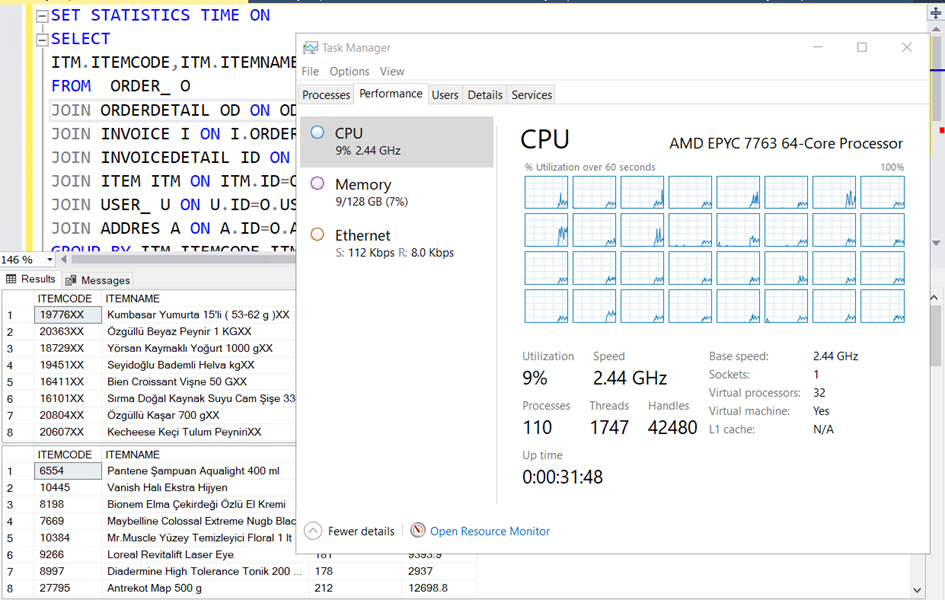
Sanki 32 cpu nun tamamını kullanıyor gibi görünüyor.
Peki gerçekte öyle mi bakalım. Bunu öğrenmek için include actual execution plan (CTRL+M) butonuna basarak sorgumuz sonucunda oluşan execution planı görebiliriz.
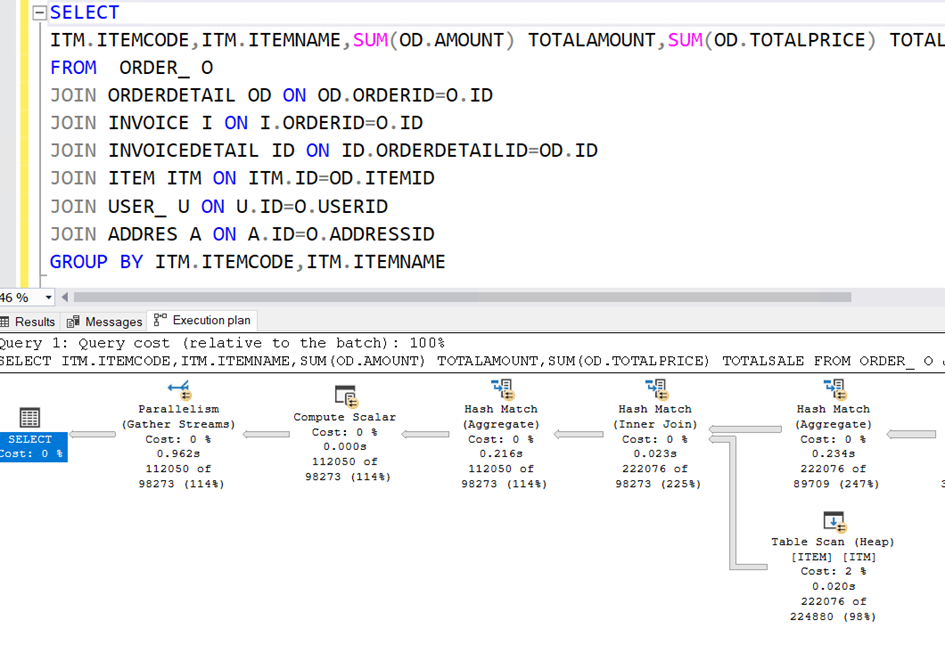
Sorgumuzu bu şekilde çalıştırdığımızda artık execution planı görebiliriz.
En baştaki select bloğunun üstünde geldiğimizde ise bu sorgu için ne kadarlık cpu kullandığını görebiliriz. Burada 32 cpu nun tamamının kullanıldığını görebiliyoruz.
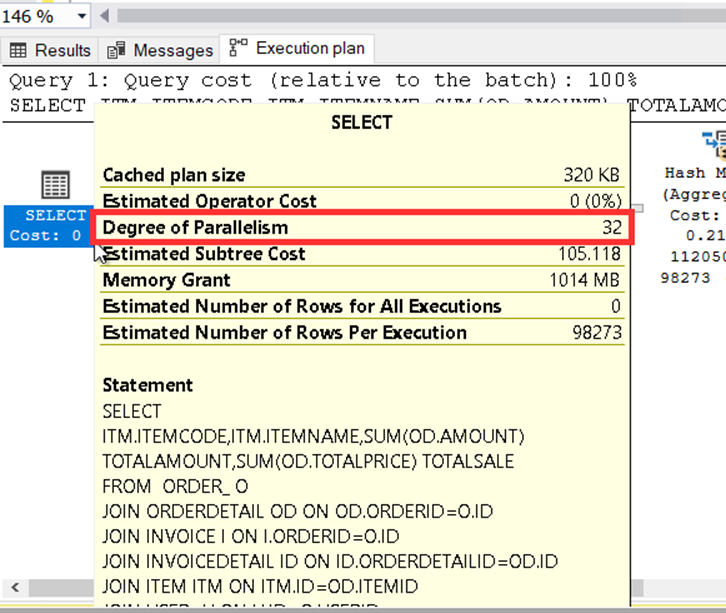
Peki bu durum olması gereken bir durum mu? Bu sorgunun acaba gerçekten 32 cpu ya ihtiyacı var mı? Ya da bu sorgu 32 cpu yu birden kullanırken başka kullanıcı ve isteklerin bu cpu lara ulaşamaması sorun yaratır mı?
İşte bu sebepler ile SQL Server’ın aynı anda tüm kaynakları kullanmasını engellemek amacı ile MAXDOP parametresi ile oynamak bir yöntemdir. Mesela database üzerinde properties dediğimizde MAXDOP parametresinin “0” olarak ayarlandığını görüyoruz. Bu, ihtiyaç halinde tüm cpu ları kullanabilirsin demek.
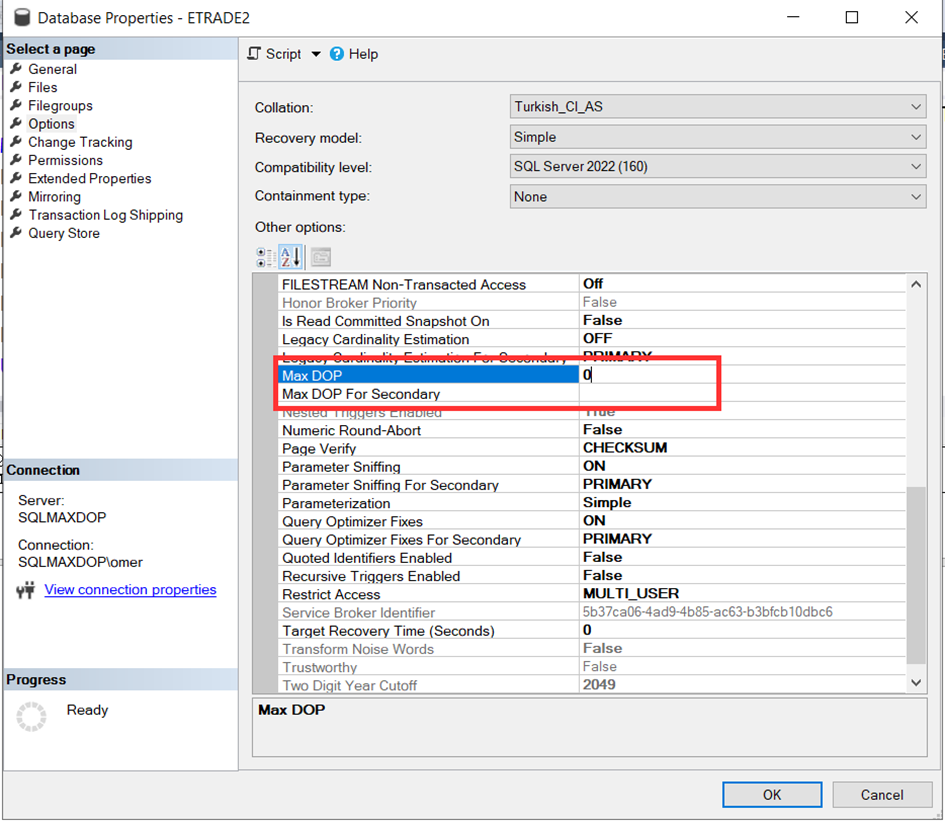
Şimdi bu ayarla oynayalım ve burasını 8 yapalım.
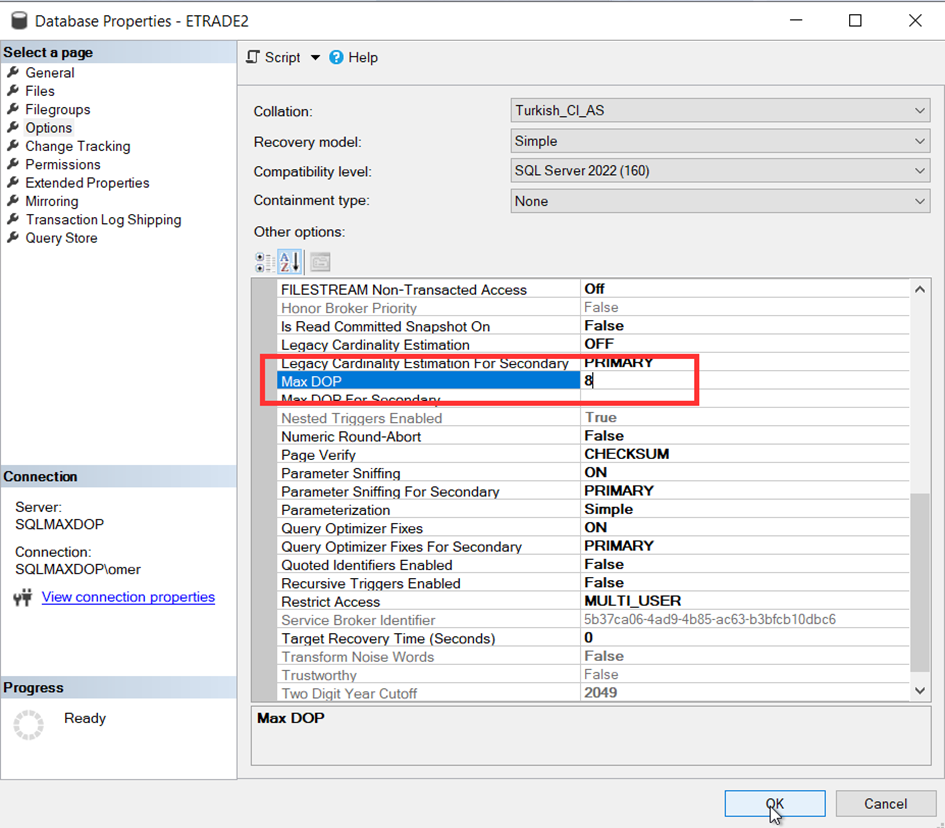
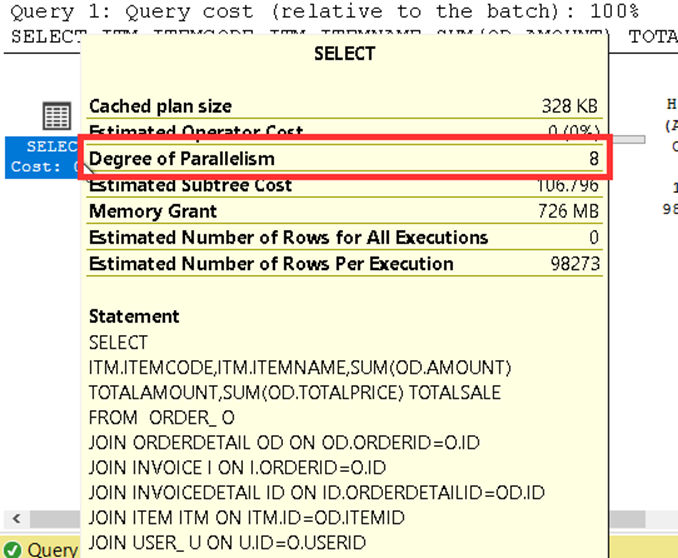
Şimdi sorgumuzu tekrar çalıştırıp hem execution plana hem de süreye bakalım.
Evet sorgumuz artık sadece 8 cpu kullanıyor.
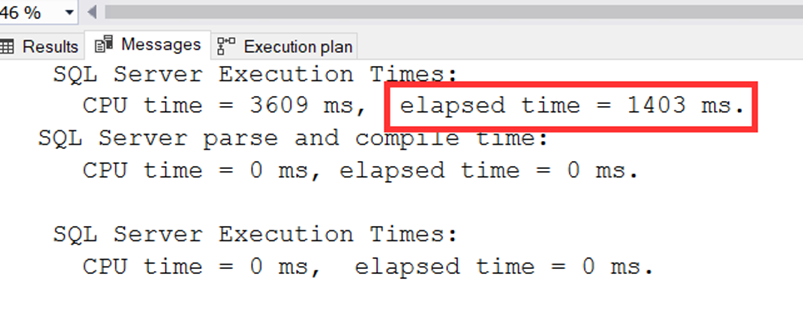
Süreye baktığımızda ise bir miktar artış var ama çok az.
Öyle ki 32 cpu da 1305 ms idi 8 cpu da ise sadece 1403 ms. Yani cpu sayısı 4 kat arttığında performansımız sadece %6 civarında artmış görünüyor. Bu durumda bu sorguda bu cpu ların tamamının kullanılması ciddi bir israf olur. Zira 1.3 saniye boyunca 32 işlemciyi meşgul etmek var, bir de 8 işlemciyi meşgul etmek var.
MAXDOP parametresini db bazında değil de sorgu bazında da beliryebiliriz. Bunu sorgunun sonuna OPTION (MAXDOP <cpu sayısı>) şeklinde yazabiliriz.
Şimdi tekrardan MAXDOP değerini sıfır yapıp cpu sınırını kaldıralım. Sonra nasıl olsa query içinde bu sınırı koyacağız.
Şimdi sorgumuzu MAXDOP 16 parametresi ile çalıştıralım.
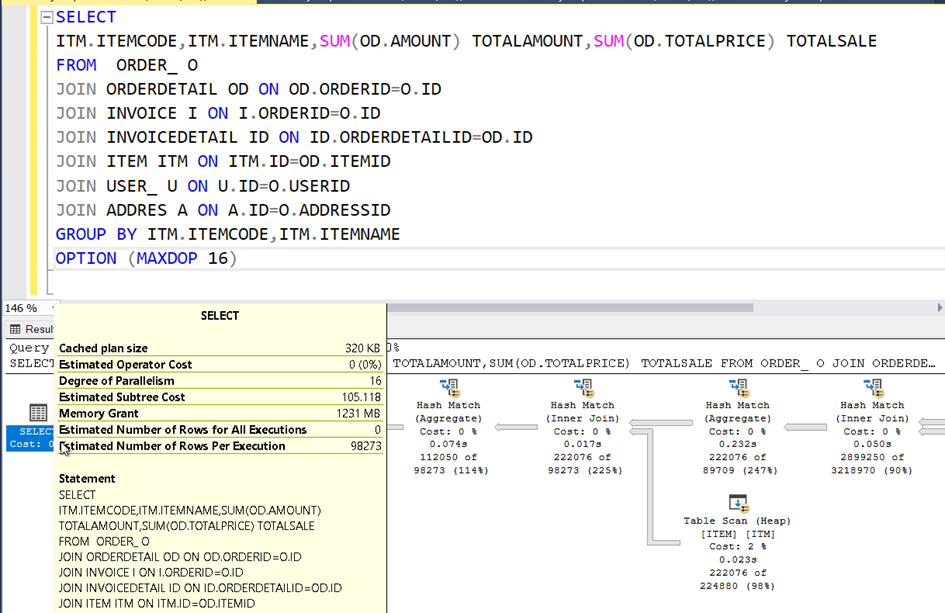
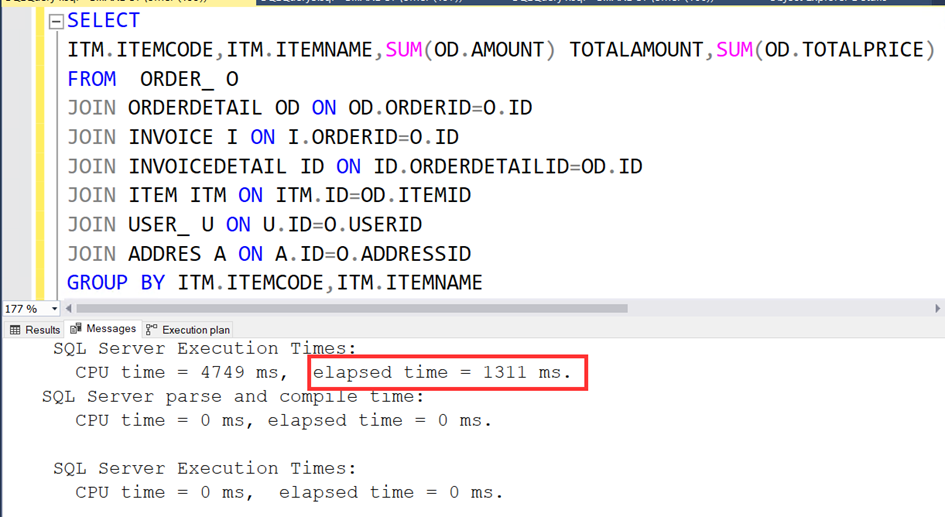
Sorgu süresi 1311 ms.
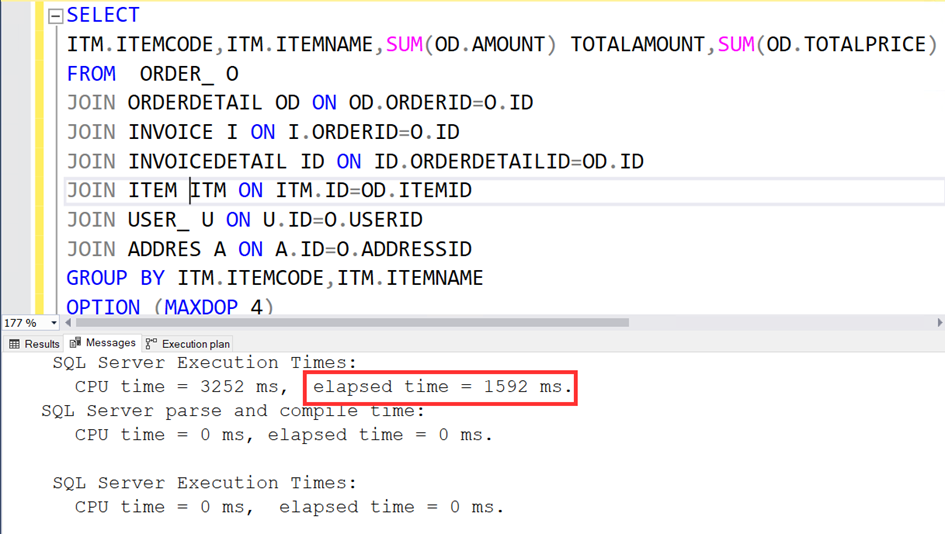
Şimdi de MAXDOP=4 ile çalıştıralım. Süre 1592 ms. Hiç fena değil.
Şimdi de MAXDOP=2 ile çalıştıralım. Süre bu kez 2192 ms. Artmaya başladı.
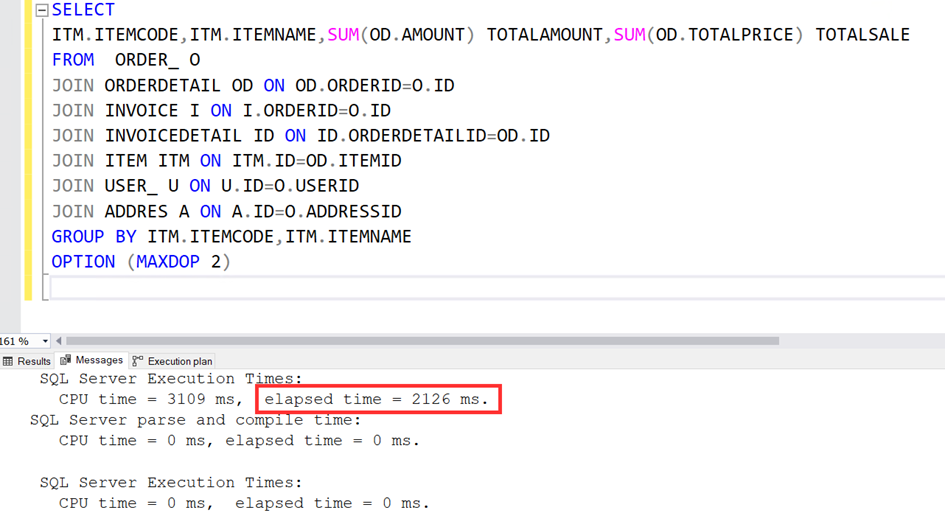
Şimdi de bu kadar joinli yapıyı 1 cpu ile çalıştıralım. Süre 4324 milisaniye. Evet daha da uzun.
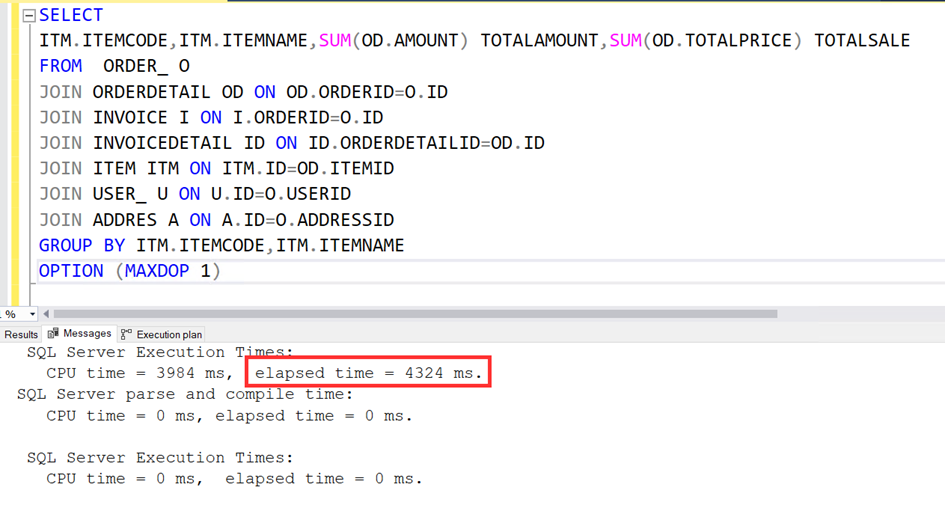
Şimdi bir hesap yapalım.
CPU Sayısı=32 iken, Süre:1305 ms
CPU Sayısı=16 iken, Süre:1311 ms
CPU Sayısı=8 iken, Süre:1403 ms
CPU Sayısı=4 iken, Süre:1592 ms
CPU Sayısı=2 iken, Süre:2126 ms
CPU Sayısı=1 iken, Süre: 4324 ms
Bu hesaba göre sanki 4 cpu kullanmak mantıklı gibi değil mi? Biz bu 4 rakamını nasıl bulduk? Deneme yanılma yaparak. En yüksektan başladık belli bir mertebeye kadar deneyerek en uygununu bulduk. Yani kendi kendimize bir geri besleme (feedback) ile bu işlemi gerçekleştirdik.
Peki gerçek dünyada bu iş nasıl olacak. Bunun gibi binlerce farklı sorgu sistemde sürekli çalışıyor. Bizler bu sorguların her birine nasıl bakacağız? İşte bu yüzden genelde yaptığımız şey MAXDOP değerini kısıtlamak oluyor. Gereksiz yere sistem fazla cpu kullanmasın diye. Ama ne kadar sınırlasak da bu kez o sınır kadar kullanabiliyor sistem.
Bu konuda çeşitli tartışmalar var. Kimisi bu MAXDOP değerinin 1 olması gerektiğini söylüyor, kimisi 4, kimisi 8. Ama tabi bu rakam aslında verinin türü ile de çok ilgili. O yüzden net birşey demek zor.
Intelligent Query Processing
SQL Server 2022 ile gelen güzel özelliklerden biri de Intelligent Query Processing (IQP). Bu konuda gelen yeniliklerden biri Parameter Sensitive Plan (PSP) Optimization idi. Bu konudaki makalemi burada bulabilirsiniz.
Intelligent Query Processing ile alakalı güzel bir özellik de bu yazının konusu olan DOP Feedback.
Peki ne yapar bu dop feedback?
Aslında yukarıda bizim yaptığımız şeyin aynısını yapar. Gelen query leri query store da saklar ve her defasında kullanılan cpu sayısını azaltarak bir geri besleme ile kendisi için en uygun dop değerini belirler.
Örneğin 32 ile başlar, 20, 16, 12 ,8 gibi değerlere bakar ve sisteme önerilerde bulunur. Böylece akıllı bir şekilde kaynakları israf etmeden performanslı şekilde kullanmayı sağlar.
Hadi birlikte yapalım.
Bu konu ile alakalı Bob Ward’ın githup sayfasındaki örneğe bakalım. Aşağıda bu sayfayı bulabilirsiniz.
https://github.com/microsoft/bobsql/tree/master/demos/sqlserver2022/IQP/dopfeedback
İhtiyacımız olanları sayalım.
Bilgisayarımızda SQL Server 2022, SSMS ve ostress.exe kurulu olmalı.
SQL Server 2022 ve SSMS in kurulu olduğunu varsayarsak ostress.exe yi aşağıdaki adresten indirip kurabilirsiniz. Bu uygulama bizim sql üzerinde stress testi yapmamız için gereken uygulama.
Yine Github’dan örnek olarak kullanacağımız database lerden WideWorldImporters db yi indiriyoruz.
İndirdiğimiz bu dosyayı c: diskinin içine c:\sql_sample_databases klasörü oluşturup buraya kopyalıyoruz.
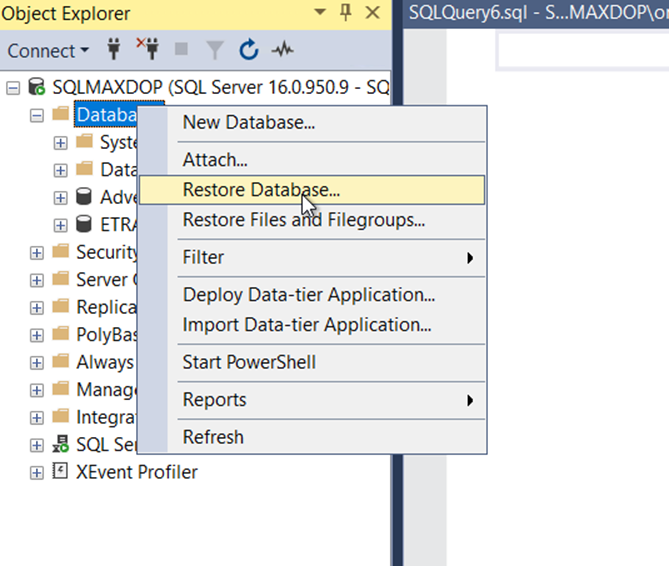
Şimdi bu db yi restore edeceğiz. Bunun için databases üzerinde sağ tık, restore database diyoruz.
Device seçip … butonuna basıyoruz.
Add diyoruz.
C:\sql_sample_databases klasöründe WorldWideImporters-Full.bak dosyasını seçiyoruz.
Database imiz başarı ile backuptan dönüldü.
Şimdi bu örnek veritabanı üzerinde biraz büyük veri oluşturacağız ki cpu farkını daha iyi görelim.
Aşağıdaki script Warehouse.StockItems tablosuna 20 milyon satır yeni kayı atacak. Normalde bu tabloda sadece 228 satır kayıt var. Bu işlem yaklaşık 15-20 dakika sürebilir.
Kullanılan kodları buradan indirebilirsiniz.
https://drive.google.com/file/d/1wSd9PFqUFVAiv3XDsqq0y1bm-MHYDBZy/view?usp=sharing
İşlem tamamlandı ve yaklaşık 18 dakika sürdü.
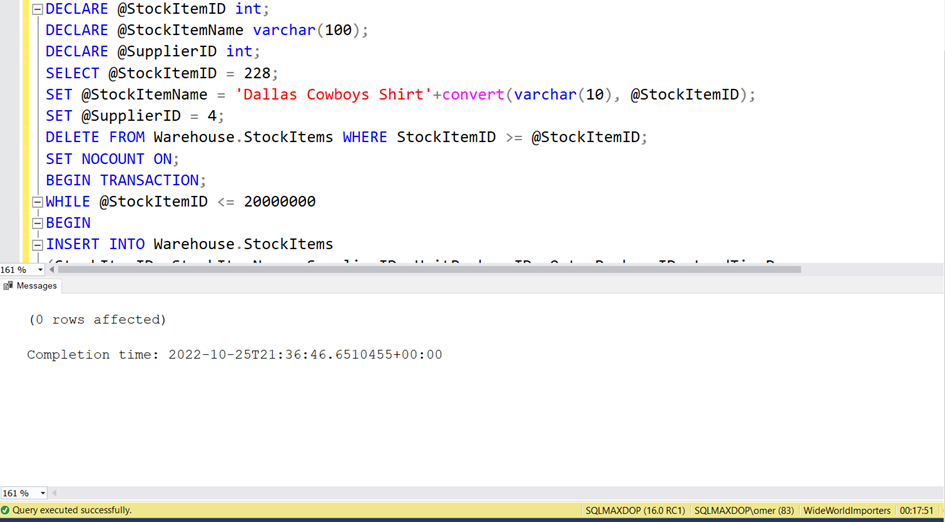
Tablomuza baktığımızda 20 milyon satır veri olduğunu görüyoruz.
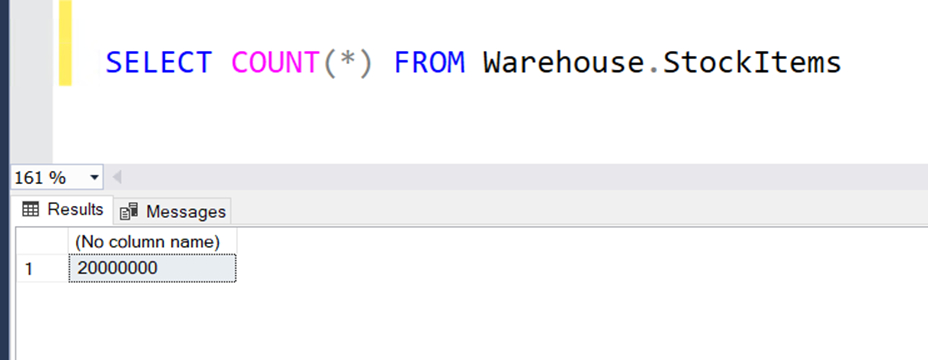
Şimdi tablomuzdaki indexi rebuild edelim.

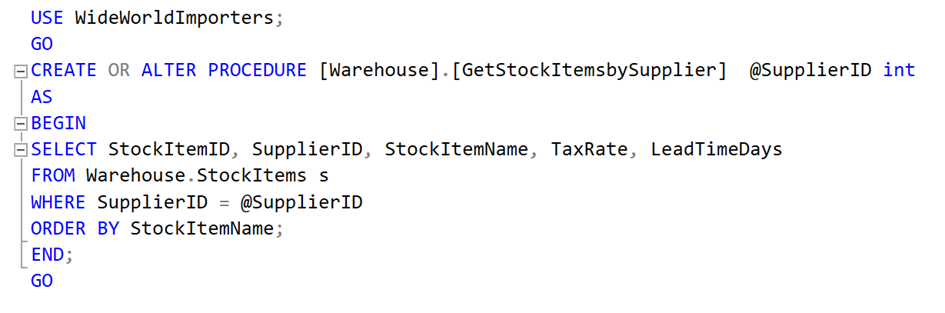
Şimdi bir stored procedure oluşturacağız. Bu procedure içine supplierID parametresi alıp ona göre ürünleri çekecek. Biz sorgumuzda supplierID olarak 4 değerini kullanacağız. Bizim içeriye attığımız 20 milyon satırın SupplierID alanı 4 olarak belirlendi.
Şimdi de database imiz üzerinde DOP Feedback için gereken ayarlamaları yapıyoruz.
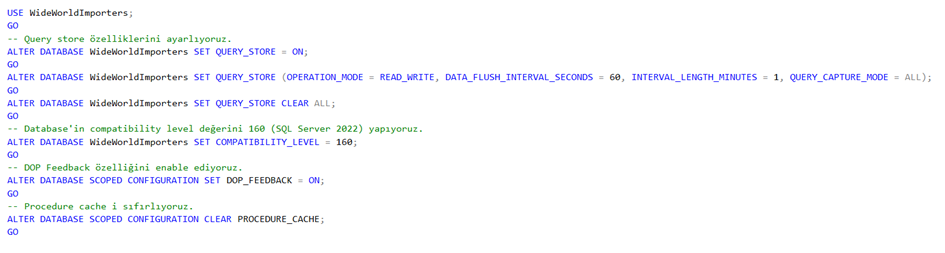
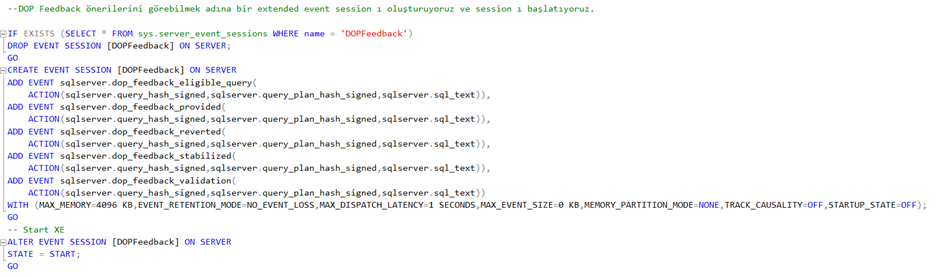
Şimdi ise DOP Feedback önerilerini ve mevcut çalışma durumunu görmek adına bir extended event session’ı oluşturuyoruz ve başlatıyoruz.
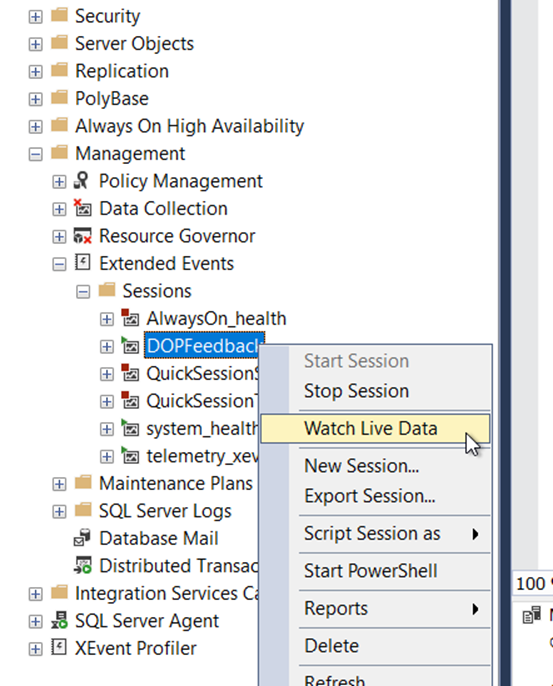
Extended event session’ı görüldüğü gibi oluştu. Watch live data diyerek izleyebiliriz. Ama şu anda herhangi birşey olmadığı için boş göreceğiz.
Şimdi command prompt’a aşağıdaki scripti yazarak sql stress testini çalıştırıyoruz. Böylece sistem 75 kere “EXEC Warehouse.GetStockItemsbySupplier 4;” sorgusunu çalıştıracak ve SQL Server bize feedback sağlayacak.
"c:\Program Files\Microsoft Corporation\RMLUtils\ostress" -E -Q"EXEC Warehouse.GetStockItemsbySupplier 4;" -n1 -r75 -q -oworkload_wwi_regress -dWideWorldImportersÇalıştırıyoruz.
Sistem çalışırken extended event session a bakıyoruz. Sistem dop_feedback’leri yakalamaya başladı. Görüldüğü gibi sistem 32 cpu nun tamamını kullanıyor. Aynı şekilde cpu time’ları da görebiliyoruz
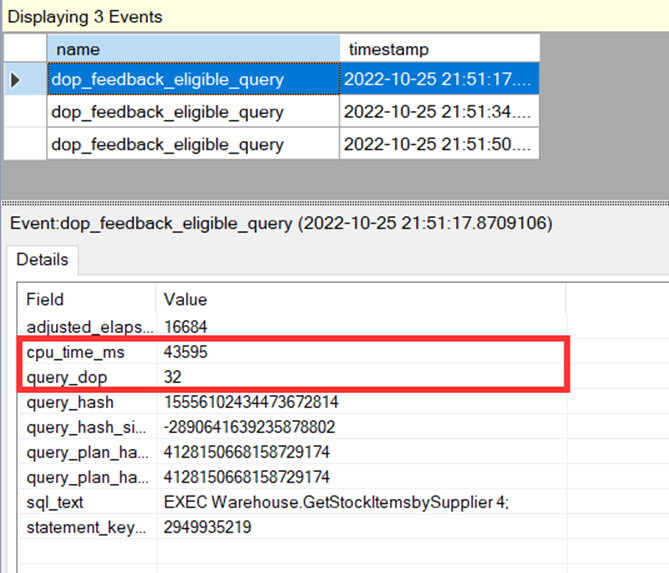
Bir müddet bekledikten sonra(bu arada sorgular çalışmaya devam ediyor) extended event session’da 20 cpu ile çalıştığını görüyoruz.
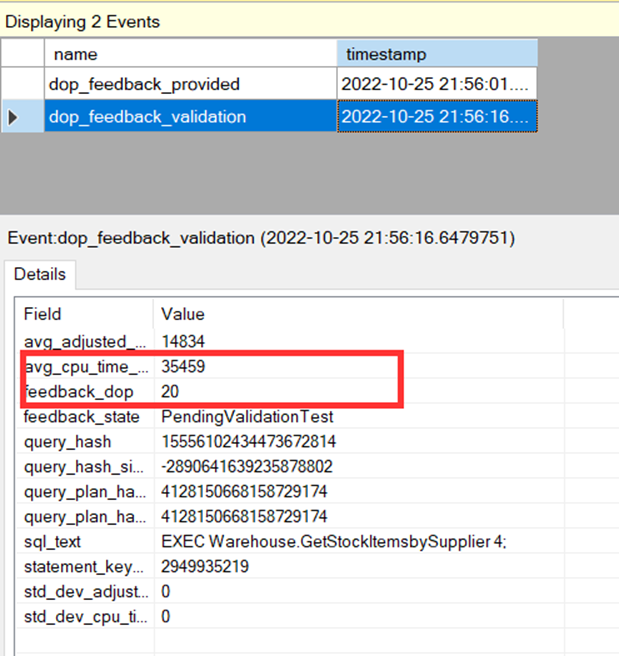
Yine biraz bekledikten sonra dop olarak 16 değerini gördük.
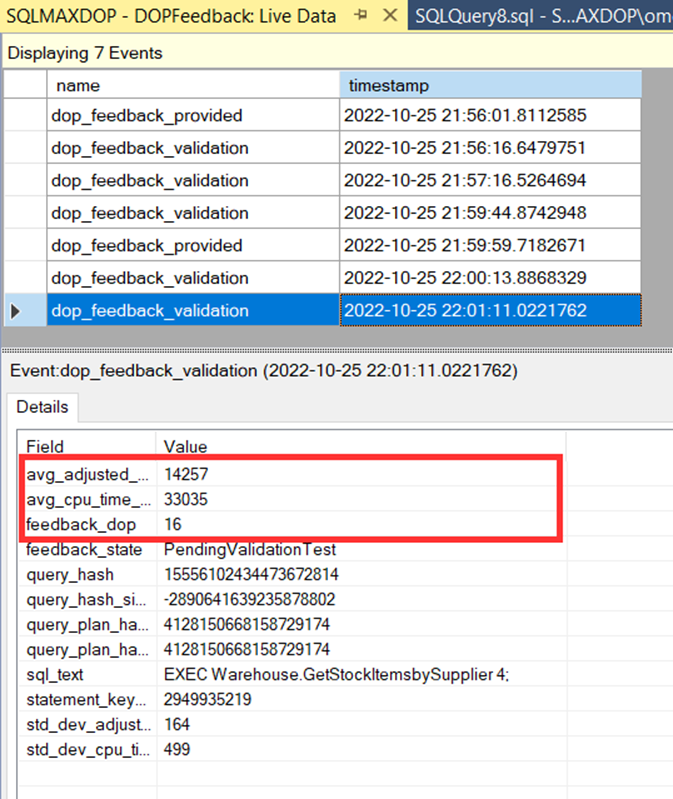
Ve son olarak yine biraz zaman geçtikçe 12 değerini görüyoruz. Yani aslında sistem otomatik olarak 12 cpu ile bu işlemin gerçekleştirilebileceğini deneme yanılma yöntemi ile bulmuş durumda.
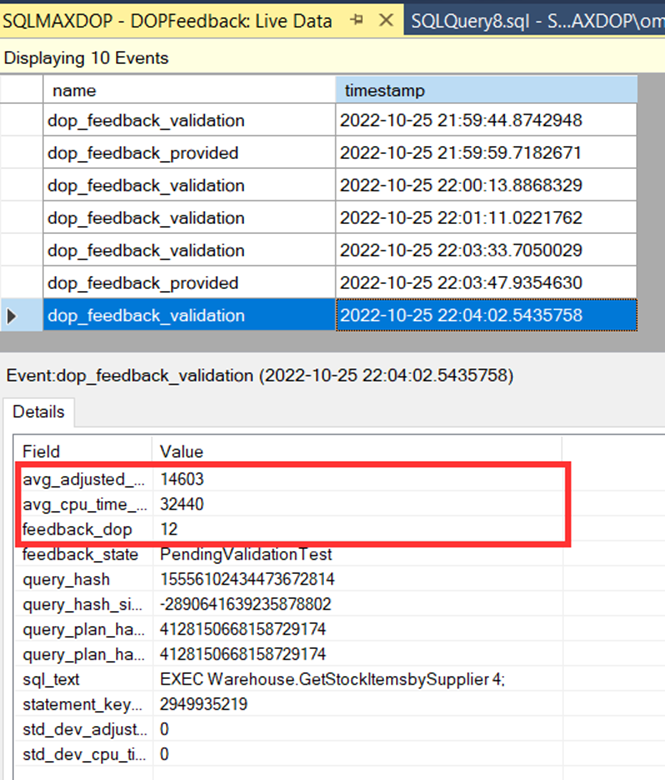
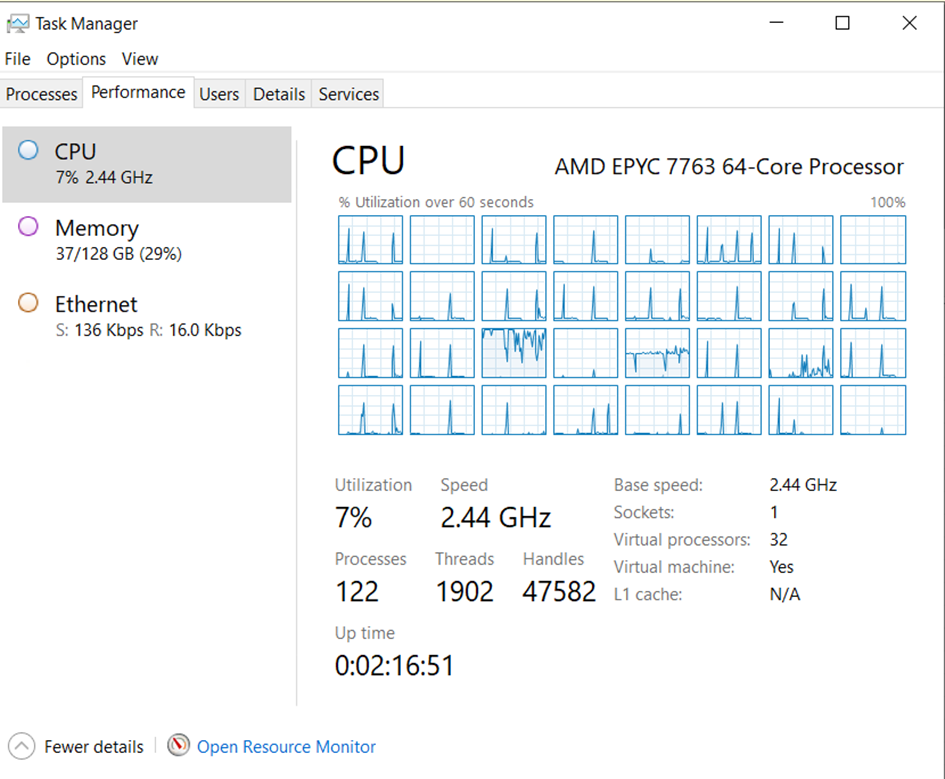
Bu durumda görev yöneticisinden baktığımızda 12 cpu nun çalıştığını görebiliyoruz. Tabi şu anda sadece bir sorgu seri şekilde çalıştığı için bu şekilde görebiliyoruz.
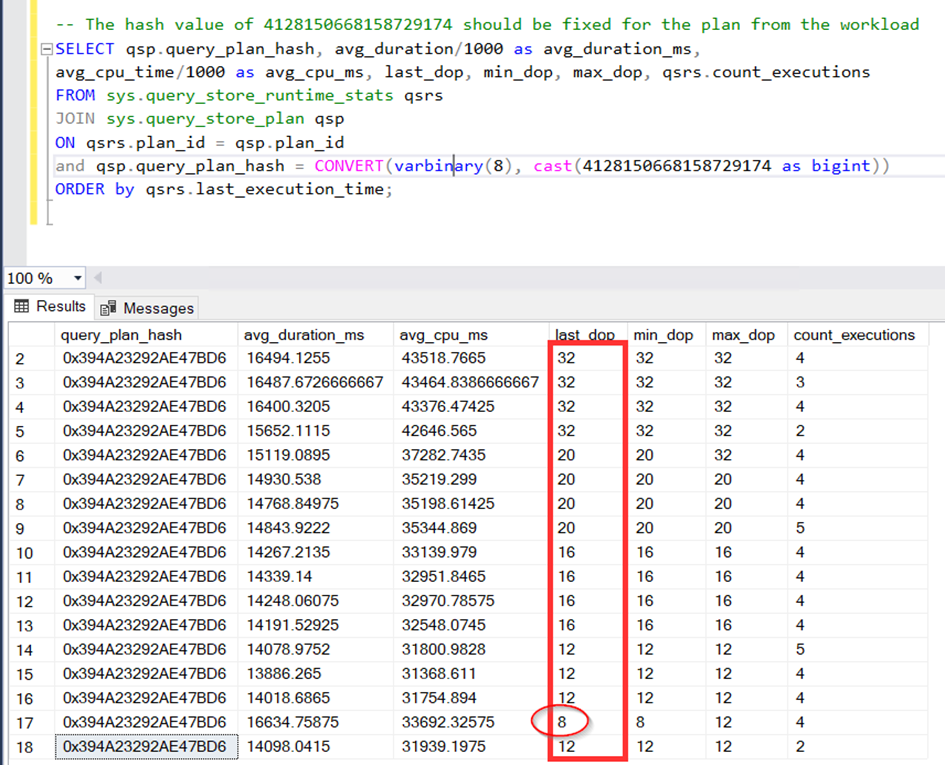
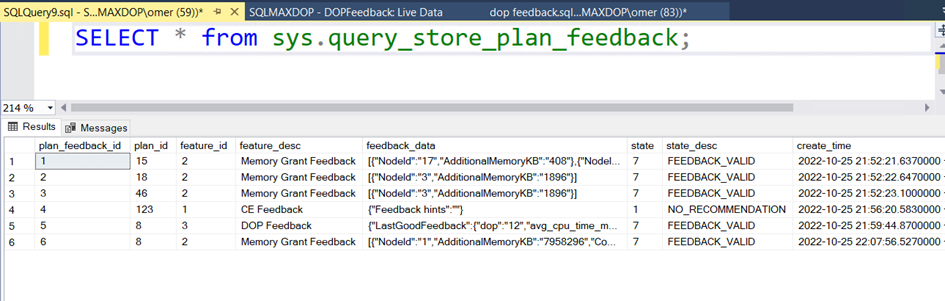
Bir diğer taraftan aşağıdaki sorgu ile de yapılan iyileştirme ve feedback leri görebiliriz.
Burada çok net bir şekilde deneme yanılma yaparak sistemin 32 den başlayıp 8’e kadar inerek 12 yi uygun dop olarak belirlediğini görebiliyoruz.
Son olarak
Komutu ile dop feedback in yanında memory ve cardinal estimation feedbacklerini de görebiliyoruz. Bunlar da başka bir makalenin konusu olsun.
Sonuç:
Bu makalemizde SQL Server 2022 ile gelen Intelligent Query Processing özelliklerinde DOP Feedback konusunu anlattık. SQL Server DOP Feedback özelliği ile bir sql sorgusunda kaç tane cpu kullanırsa en verimli şekilde çalışacağını hesaplamakta ve bu geri beslemelerle doğru DOP değerini bulabilmektedir.
Gerçekten kullanışlı bu özelliği bize sundukları için SQL Server geliştiricilerine teşekkürlerimizi iletiyoruz.
Makaleyi beğendiğinizi ümit ediyorum.
Bir sonraki makalede görüşmek dileğiyle…








Eline sağlık Ömer Hocam, çok güzel bir makale olmuş.